阿里巴巴、Facebook、Cloudera等巨头的数据收集框架全攻略
互联网的发展,带来了日新月异的业务种类,随着业务的增长,随之而来的,是业务日志指数的递增。一些公司每条业务线, 提供服务的线上服务器就达几百台之多, 每天的日志量超百亿。如何能够将散落在各服务器上的日志数据高效的收集汇总起来, 成了在数据分析处理之前必须解决的问题。
一个优秀的数据收集框架,需要具备三点特性,一是低延迟,二是可扩展,三是容错性。
- 低延迟:从Log数据产生到能够对其做分析,希望尽可能快的完成数据的收集。在批处理或者离线分析中,对数据的实时性要求并不高,但是随着大数据的发展,实时计算的能力越来越强,实时分析的场景也越来越多,所以对日志收容的实时性要求也越来越高。
- 可扩展性:日志分布在服务器集群上,由于业务或者系统的原因,集群的服务器会发生变化,如上线,下线,宕机等,Log收集框架需要能够相应的做出变化,易扩展,易部署。
- 容错性:Log收集系统需要满足大的吞吐以及承受足够的压力, 这就意味着Log收集系统很可能面临宕机的风险, 在这种情况下, Log系统需要有不丢失数据的能力。
各大互联网巨头都开发了自己的日志收集工具, 比如Apache的chukwa,Facebook的scribe,Cloudera的flume以及ELK stack(归属于Elastic.co公司)组合中的logstash,都是目前比较流行的开源的日志收集框架。
除此之外,Linkedin的kafka 和 阿里的TT(TimeTUnel), 也是高效的数据传输框架,在其基础上,可以方便地搭建出高性能的数据收集框架。阿里通过TT搭建的数据收集系统,服务了一半以上的公司业务, 同时TT在HBase的支撑下,还可以作为大吞吐的消息队列来使用。
接下来,我们就来逐一的了解一下这些数据收集框架。
chukwa
chukwa 是Apache 开源的针对大规模分布式系统的日志收集和分析的项目, 它建立在hdfs以及mr框架的基础上,完全继承了Hadoop的扩展性和稳定性。chukwa还包括了一系列组件,用于监控数据,分析数据和数据可视化等。 架构图如下:
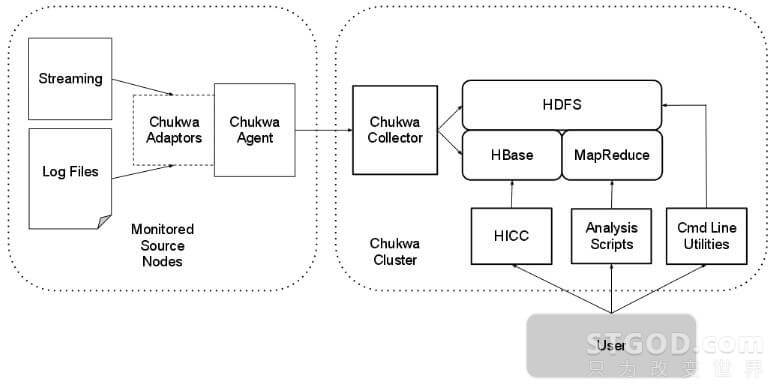
从架构图上可以看出, chukwa大致分为五个部分:
- Hadoop和HBase集群,用于chukwa处理数据
- 一个或多个agent进程, 将监控的数据发送到HBase集群。 启动有agent进程的节点被称作监控源节点
- Solr云集群,用于存储索引数据文件
- 数据分析脚本, 概括Hadoop集群的健康状况
- HICC, chukwa的可视化工具
由于依赖于mr去处理数据,所以chukwa效率注定不会太高,整个数据流在数据处理间断吞吐量急剧下降。 另外,chukwa设计时就没有将它定位为单纯的日志收集工具,而是囊括数据的分析处理, 数据可视化等功能的完整的数据分析框架, 在这样的设计思路下, 数据收集和数据分析俩大任务在优化目标上并不相同,甚至有可能相悖。所以优化效果并不明显。
与其如此,还不如专一的定位在数据收集领域,数据分析和处理等交给其他成熟的框架来实现, 如Hive、Impala等。 也出于这些原因,chukwa并没有被广泛的使用。
scribe
scribe 是Facebook开源的日志收集系统,在facebook内部被广泛使用。 scribe主要用于收集汇总日志流,易扩展,并且能够保证在网络和部分节点异常情况下的正常运行。 其架构图如下:
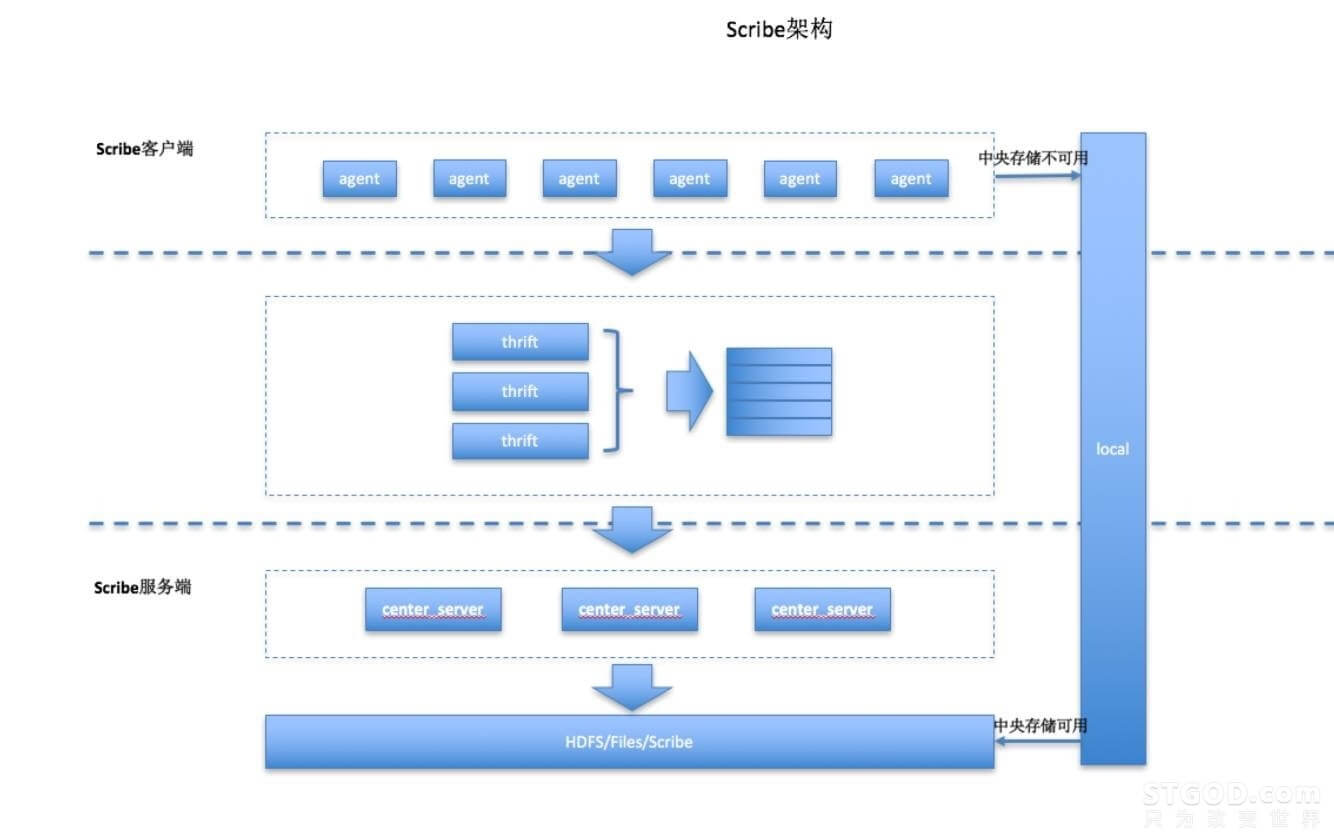
应用系统中每一台日志服务器都会部署scribe服务, scribe服务收集节点信息,并将数据发送到scribe中央服务, scribe中央服务是多组scribe服务集群。如果scribe中央服务不可用,本地的scribe服务就会将信息写到本地磁盘,当中央服务可用时重新发送。 scribe中央服务将数据写入到最终的目的地,典型的存储包括nfs或者dfs, 当然,也可以重新写到下一个scribe服务中。
scribe将客户端日志组织为类目和信息两个部分,以此来唯一确定一条消息。 类目用来描述信息预计的目标位置, 可以通过scribe server中配置来指定。 类目同样也支持前缀方式的配置, 默认可以在文件路径中插入类目名称。scribe在一些特定case下会丢失数据:
- 如果客户端的scribe既不能连接到本地文件系统,也不能连接到scribe中央服务器
- 如果客户端scribe服务崩溃, 会造成内存中的少量数据丢失,但磁盘数据不会丢失
- 多种情况并发,如重发服务无法连接到任何的中央服务器,而且本地磁盘已满
- 小概率的延迟导致的消息冲突
从架构图上可以看到,agent是作为thirft的客户端与scribe中央服务器通信的,这样做的好处显而易见, 我们可以采用多种编程语言来开发我们的数据收集客户端,具备较大的灵活性。但是依赖于thirft框架,其稳定性与吞吐量受到了thirft的制约, 同时引入消息队列, 整个收集框架略显承重。
flume
说起flume 大家并不陌生,flume是目前使用的比较广的日志收容工具。 先说说flume的历史,flume早期是由cloudera 开发设计的, 目前将其早期的版本称为flume-og。 随着大数据的发展,flume的 工程代码变得越来越臃肿, 再加上核心组件设计不合理、核心配置不标准等,造成flume的越来越不稳定。 2011年10月22号,cloudera 完成了Flume-728,对 Flume 进行了大刀阔斧的改造,随后被纳入Apache阵营,更名为Apache Flume,开启了flume-ng的时代。
我们首先来看一下flume-og是怎样的一个存在。
flume-og架构图:

从架构图上我们可以了解到, flume-og 有三种角色的节点,代理节点(agent)、收集节点(collector)、主节点(master),agent 从各个数据源收集日志数据,将收集到的数据集中到 collector,然后由收集节点汇总存入 hdfs。master 负责管理 agent,collector 的活动。 仔细看,我们会返现, agent、collector 都由 source、sink 组成,代表在当前节点数据是从 source 传送到 sink, 这也就意味着,节点中没有专门的缓存数据的模块,节点之间的数据阻塞极易发生, 再加上,数据流经的缓解太多,必然会对吞吐造成影响。同时, 为了提高可用性, 引入zk来管理 agent, collector, master的配置信息,大大增加了使用和维护的成本。
flume-ng架构图:
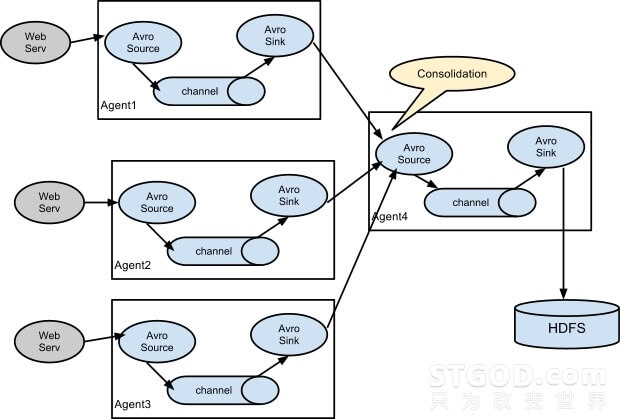
flume-ng节点组成:
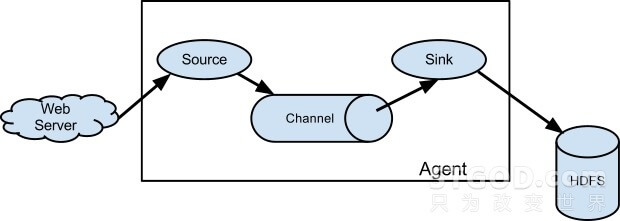
改版后的flume-ng, 只保留了一种角色的节点,代理节点(agent), 没有了collector和master节点,这是核心组件最核心的变化,大大简化了部署和维护的成本。 同时将节点由之前的source, sink升级到现在的source, channel, sink三部分,channel专门用于传输过程中数据的暂时缓存。
flume-ng不在依赖于zk,更加灵活,轻便。自带多种类型插件,可以从多种数据源中收集数据,将数据送入到指定的目标存储中, 借助自定义source,channel和sink,不断可以扩展数据收集的source,channel,sink类型,还可以实现除日志收集之外的其他功能。 不同类型的agent直接可以相互连接,形成Pipeline, 完成更加复杂的功能。 这也是flume-ng越来越流行的重要原因。
logstash
logstash 是基于实时数据管道能力的数据收集引擎, 它可以从不同的数据源整理数据,统一写入到你选择的目标存储中。 清洗和规范你的数据,方便下游分析和可视化使用。
架构图如下:

从架构图看,logstash和flume-ng的设计思想很相似, flume-ng的agent由source,channel,sink三部分组成, 而logstash实例由input,filter和output三部分组成。 input同source一样,用于从数据源中收集数据。 filter和channel略有不同,filter是对input收集上来的数据做一定的处理后交给output。 默认的filter有 grok filter(用于结构化数据), mutate filter(用于更改数据结构,如数据字段更名,移除,替换等),drop filter(彻底删除数据),clone filter(拷贝数据), geoip filter(通过ip地址获取额外的信息)等。 output将filter处理后的数据送入的指定的存储或者下一个logstash的实例。
logstash同flume-ng一样,在实现日志收集功能的基础上,通过实现和更改logstash的input, filter, 和output插件, 可以将一些我们想要的功能,很方便的嵌入到数据收集的整个过程中, 加速我们对大量的多样话数据的感知能力。
大多数情况下, logstash作为elk套件的日志收集框架,实现实时日志分析时使用。
kafka
kafka 是Linkedin 2010开源的基于发布订阅模式分布式消息系统,之后加入Apache阵营,更名为Apache kafka。其架构如下:

整个系统由三部分节点组成:
- producer:产生指定topic的消息
- broker:在磁盘上存储维护各种topic的消息队列
- comsumer:订阅了某个topic的消费者从broker中拉取消息并进行处理
broker对topic的管理是基于顺序读写磁盘文件而实现的,在kafka内部,支持对topic进行数据分片(partition), 每个数据分片都是一个有序的, 不可更改的尾部追加消息队列。队列内每个消息都被分配一个在本数据分片的唯一ID,也叫offset, 消息生产者在产生消息时可以指定数据分片, 具体方法可以采用round robin 随机分配, 也可以根据一定的应用语义逻辑分配, 比如可以按照用户uid进行哈希分配,这样可以保证同一用户的数据会放入相同的队列中, 便于后续处理。 也正因为如此, kafka有着极高的吞吐量。 在kafka的基础上实现日志收容有着天然的优势:
- 方便实现:开发收集数据的producer和写数据的consumer即可, producer从日志服务器上收集日志,送入broker, consumer从broker拉取数据,写入到目标存储
- 高性能:天然的高吞吐,较强的可扩展性和高可用性, 消息传递低延迟
TT(Timetunel)
是阿里开源的实时数据传输平台,基于thrift通讯框架实现,具有高性能、实时性、顺序性、高可靠性、高可用性、可扩展性等特点。
其架构如下:

整个系统大概分四部分:client,router, zookeeper,broker
- client:用户访问timetunnel的接口,通过client用户可以向timetunnel发布消息,订阅消息。
- router:timetunnel的门户,提供安全认证、服务路由、负载均衡三个功能。router知道每个broker的工作状态,router总是向client返回正确的broker地址。
- zookeeper:timetunnel的状态同步模块,router就是通过zookeeper感知系统状态变化,例如增加/删除broker环、环节点的增删、环对应的topic增删、系统用户信息变化等。
- broker:timetunnel的核心,负责消息的存储转发。broker以环的形式组成成集群,可以通过配置告知router哪些数据应该被分配到那个集群,以便router正确路由。环里面的节点是有顺序的,每个节点的后续节点自己的备份节点,当节点故障时,可以从备份节点恢复因故障丢失的数据。
和kafka类似,TT自身也只是一个数据传输的工具,并没有日志采集的功能,但是在它的架构之上,我们很容易去构造一个高性能,大吞吐的数据收集工具。

如上图,tt实现的收容框架,大致分为三部分:
- clientAgent:基于TTclientAPI 实现的日志收容客户端,被安装在日志服务器上,用于收集数据并将数据送入到消息通讯层;如TailFIle agent, 通过linux的notify机制,监控文件变化,将数据实时的送入消息通讯层
- 消息通讯层:有client agent收集上来的数据,经过tt集群传输后,以一定的数据格式暂时存入底层HBase集群。 消息通讯层,还实现了发布订阅的消息机制, 通过TTclientAPI可以订阅消息通讯层的数据.
- DeepStorage:通过订阅消息通讯层数据,通过不同的writer将数据写入到不同的存储中,用于接下来的分析处理
我相信大家现在对这几种框架有了初步的了解了,在开始自己的数据分析之旅前,请根据自己的业务需要,选择合适的收集框架。
作者:STGOD
转载请标明出处:https://stgod.com/2941/