在Python3.5下安装和测试Scrapy爬网站
. 引言
Scrapy框架结构清晰,基于twisted的异步架构可以充分利用计算机资源,是爬虫做大的必备基础。
本文将讲解如何快速安装此框架并使用起来。
2. 安装Twisted
2.1 同安装Lxml库
(参考《为编写网络爬虫程序安装Python3.5》3.1节)一样,通过下载对应版本的.whl文件先安装twisted库,下载地址: http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted

2.2 安装twisted
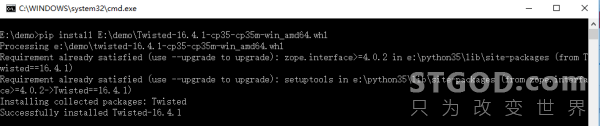
打开命令提示符窗口,输入命令:
pip install E:demoTwisted-16.4.1-cp35-cp35m-win_amd64.whl(下载好的twisted模块的whl文件路径)
3. 安装scrapy
twisted库安装成功后,安装scrapy就简单了,在命令提示符窗口直接输入命令: pip install scrapy 回车
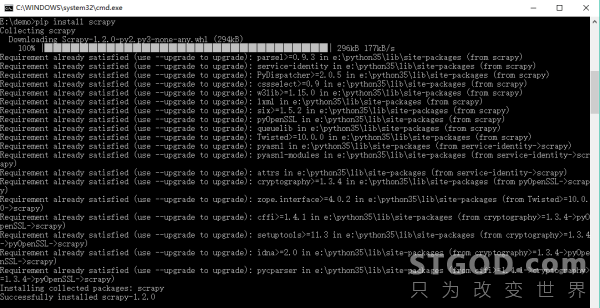
安装关联模块pypiwin32,在命令提示符窗口直接输入命令: pip install pypiwin32 回车

4. Scrapy测试,敲一个基于Scrapy框架的爬虫程序
新建一个Scrapy爬虫项目fourth(因为这是继Python3.5安装的第四篇教程,有兴趣的话请从头看起):在任意目录按住shift+右键->选择在此处打开命令提示符窗口(这里默认为E:demo),然后输入命令:
E:demo>scrapy startproject fourth

该命令将会创建包含下列内容的fourth目录:
fourth/
scrapy.cfg
fourth/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
修改项目配置文件settings.py,有些网站会在根目录下放置一个名字为 robots.txt的文件,里面声明了此网站希望爬虫遵守的规范,Scrapy默认遵守这个文件制定的规范,即ROBOTSTXT_OBEY默认值为 True。
在这里需要修改ROBOTSTXT_OBEY的值,找到项目目录(这里为:E:demofourthfourth)下文件 settings.py,更改ROBOTSTXT_OBEY的值为False
引入Gooseeker最新规则提取器模块gooseeker.py(下载地址: gooseeker/core at master · FullerHua/gooseeker · GitHub),拷贝到项目目录下,这里为E:demofourthgooseeker.py
创建爬虫模块,进入项目目录E:demofourth下,在此处打开命提示符窗口输入命令:
E:demofourth>scrapy genspider anjuke 'anjuke.com'

该命令将会在项目目录E:demofourthfourthspiders下创建模块文件anjuke.py,以记事本打开然后添加代码,主要代码:
# -*- coding: utf-8 -*-# Scrapy spider 模块# 采集安居客房源信息# 采集结果保存在anjuke-result.xml中import osimport timeimport scrapyfrom gooseeker import GsExtractorclass AnjukeSpider(scrapy.Spider):
name = "anjuke"
allowed_domains = ["'anjuke.com'"]
start_urls = (
'http://bj.zu.anjuke.com/fangyuan/p1',
)
def parse(self, response):
print("----------------------------------------------------------------------------")
# 引用提取器
bbsExtra = GsExtractor()
# 设置xslt抓取规则
bbsExtra.setXsltFromAPI("31d24931e043e2d5364d03b8ff9cc77e", "安居客_房源")
# 调用extract方法提取所需内容
result = bbsExtra.extractHTML(response.body)
# 打印采集结果
print(str(result).encode('gbk','ignore').decode('gbk'))
# 保存采集结果
file_path = os.getcwd() + "/anjuke-result.xml"
open(file_path,"wb").write(result)
# 打印结果存放路径
print("采集结果文件:" + file_path)
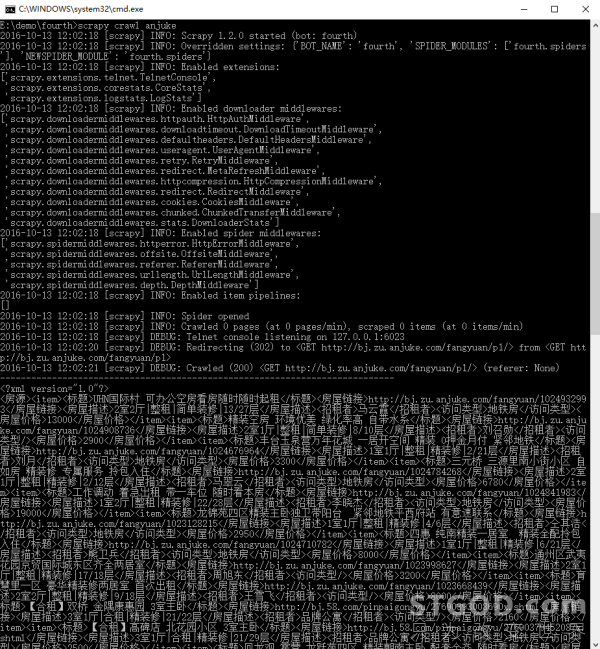
启动爬虫,进入项目目录E:demofourth下,在此处打开命提示符窗口输入命令:
E:demofourth>scrapy crawl anjuke
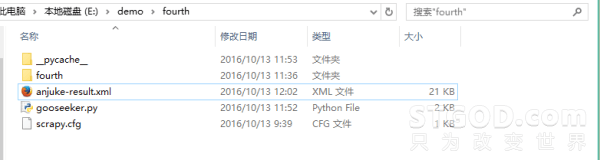
查看保存结果文件,进入Scrapy爬虫项目目录,这里为E:demofourth,找到名称为anjuke-result.xml的文件夹然后打开
5. 总结
安装pypiwin32时碰到了一次超时断开,再次输入命令重新安装才成功,若重复安装都失败 可以尝试连接vpn再安装。
下一篇《Python爬虫实战:单页采集》将讲解如何爬取微博数据(单页),同时整合Python爬虫程序以 Gooseeker规则提取器为接口制作一个通用的采集器,欢迎有兴趣的小伙伴一起交流进步。
6. 集搜客GooSeeker开源代码下载源
GooSeeker开源Python网络爬虫GitHub源
作者:STGOD
转载请标明出处:https://stgod.com/2821/