反爬虫和抗DDOS攻击技术实践
导语
企鹅媒体平台媒体名片页反爬虫技术实践,分布式网页爬虫技术、利用人工智能进行人机识别、图像识别码、频率访问控制、利用无头浏览器PhantomJS、Selenium 进行网页抓取等相关技术不在本文讨论范围内。
Cookie是什么
大家都知道http请求是无状态的,为了让http请求从“无状态” to “有状态” , W3C 在 rfc6265 中描述了整个http协议的状态机制,既从客户端(通常是浏览器)到服务器端的流转过程,cookie 的引入使得 服务器在 接收到请求时可以区分用户和状态。
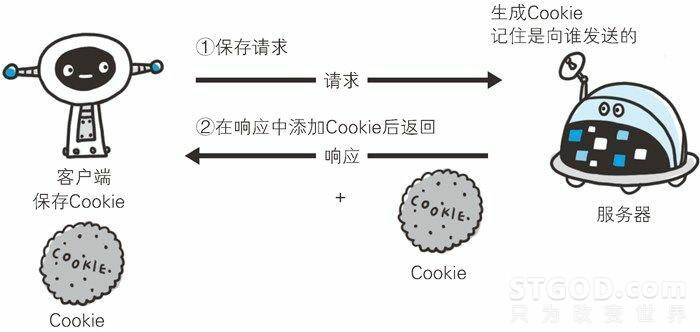
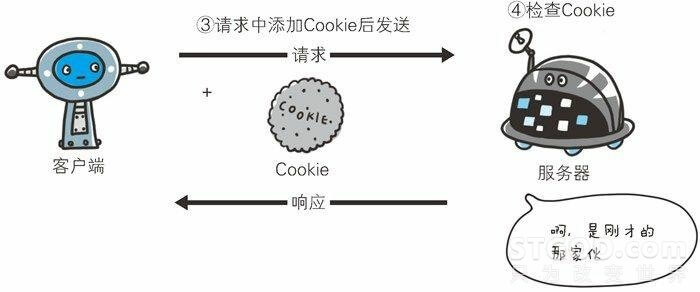
通过上边这张图,我们可以容易的发现,这个过程就好像“上车打票”一样,有普通票(不记名)和 也月票(“记名的票”),有位伟大的程序员曾经说过“如果你的程序逻辑和实际生活中的逻辑反了,就一定是你错了”。
言归正传,为什么反爬虫
互联网有很多业务或者说网页,是不需要用户进行登录的(不记名的票),你可以简单的认为这其实是一个“不需要记录http状态的业务场景”(注意这里是简单认为,但其实并不是无状态的),那这些不需要登录的页面,往往又会包含大量的聚合信息,比如新闻门户网站、视频门户网站、搜索引擎,这些信息是公开的,其实是可以可以被爬虫抓取的,站长甚至还要做SEO(搜索引擎优化)让搜索引擎或其他网站更多更经常的去收录自己的整站,以便推广,那既然我们要做SEO优化为什么还要 “反爬虫” ?
因为通过程序进行 URL 请求 去获得数据的成本是很低的,这就造成大量抵质量网页爬虫在网络横行,对业务方的服务器造成不必要的流量浪费和资源消耗。
网页爬虫到底有多容易
正常打开的界面内容是这样的

查看网页源代码,看看我们要抓取的目标,这里就不在演示了,然后利用Chrome开发者工具提供的 “Copy as curl”
curl 'https://v.qq.com/' -H 'Pragma: no-cache' -H 'DNT: 1' -H 'Accept-Encoding: gzip, deflate, sdch, br' -H 'Accept-Language: zh-CN,zh;q=0.8,en-US;q=0.6,en;q=0.4' -H 'Upgrade-Insecure-Requests: 1' -H 'User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36' -H 'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8' -H 'Cache-Control: no-cache' -H 'Cookie: tvfe_boss_uuid=ad12b5df44c4af49; ad_play_index=34; pgv_info=ssid=s9710442890; ts_last=v.qq.com/; pgv_pvid=7925047056; ts_uid=578794400; qv_als=778esxpJSKmr5N0bA11491899166PnRBKw==' -H 'Connection: keep-alive' --compressed
然后你会发现,与“查看网页源代码” 没有区别,说明我们已经成功获得数据内容。
反爬虫效果是什么样的?
我们通过浏览器直接打开下面这个链接 ,会发现请求到的结果是个JSON
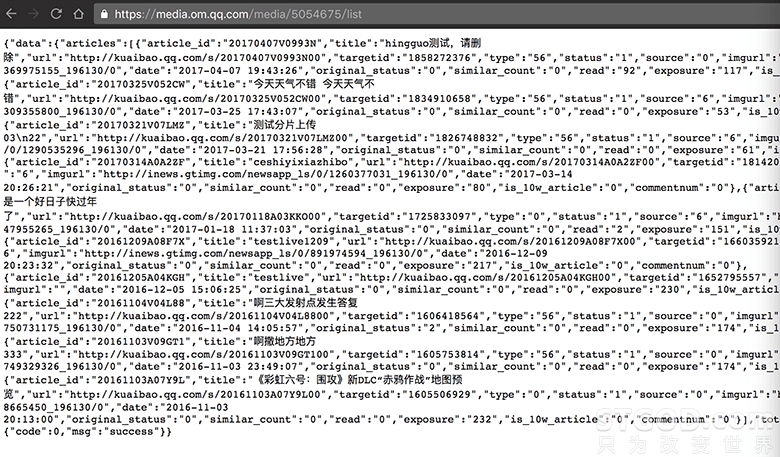
现在我们重复刚刚的 “Copy as curl” 的过程,看看是否依然能获得正确结果 ? 答案是否定的,我们来验证一下
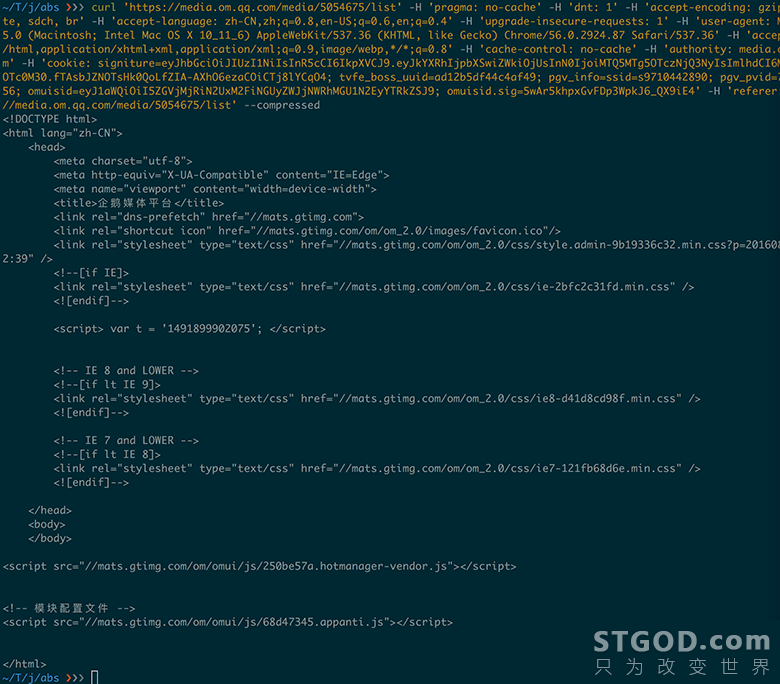
curl 'https://media.om.qq.com/media/5054675/list' -H 'pragma: no-cache' -H 'dnt: 1' -H 'accept-encoding: gzip, deflate, sdch, br' -H 'accept-language: zh-CN,zh;q=0.8,en-US;q=0.6,en;q=0.4' -H 'upgrade-insecure-requests: 1' -H 'user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36' -H 'accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8' -H 'cache-control: no-cache' -H 'authority: media.om.qq.com' -H 'cookie: signiture=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJkYXRhIjpbXSwiZWkiOjUsInN0IjoiMTQ5MTg5OTczNjQ3NyIsImlhdCI6MTQ5MTg5OTc0M30.fTAsbJZNOTsHk0QoLfZIA-AXhO6ezaCOiCTj8lYCqO4; tvfe_boss_uuid=ad12b5df44c4af49; pgv_info=ssid=s9710442890; pgv_pvid=7925047056; omuisid=eyJ1aWQiOiI5ZGVjMjRiN2UxM2FiNGUyZWJjNWRhMGU1N2EyYTRkZSJ9; omuisid.sig=5wAr5khpxGvFDp3WpkJ6_QX9iE4' -H 'referer: https://media.om.qq.com/media/5054675/list' --compressed
我们会发现得到的是一个网页而不是 JSON,命中了反爬虫逻辑
到底发生了什么?
前面提到了 “不记名票据” 和 因推广需求网站不需要登录的场景,那针对这样的情况,是否我们就真的不需要对请求进行签名呢 ? 答案是否定的,不花钱或花很少的钱就可以免费进入公园游玩了,游客可能本身是感受不到“票据”的存在,但其实我们还是需要对用户进行标记,这里发散一下,其实统计网站在追踪pv/uv时也是进行了类似的“标记”,下面我们通过一张图来描述下上面请求发生的过程
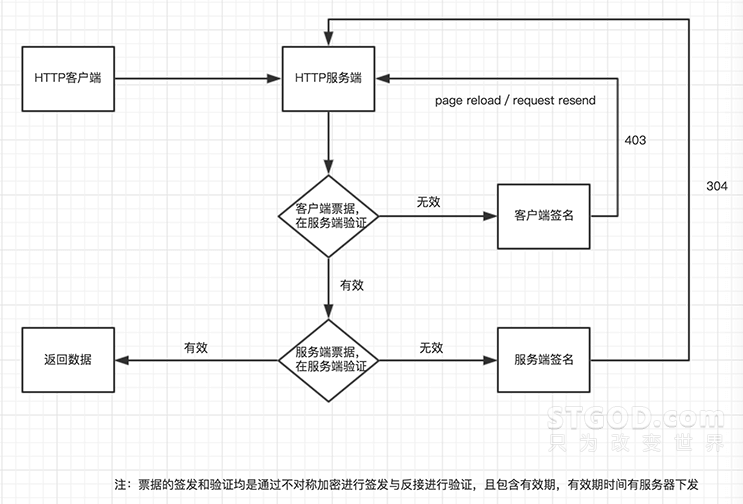
这里我们有两次签名过程,一次在服务器端进行,一次在客户端进行,因为在这个页面是不需要用户登录,所以在服务器端进行签名,对于爬虫来说是一个几乎没有成本的过程,它可以每次来“园子”里玩的时候,都申请一张新的票,伪装成为一个“新的用户”,为了应对如此低廉的成本,我们增加“客户端进行签名”的流程,有人说“客户端签名是不靠谱的,因为你的代码别人都是可以看到的是可以破解的”,这个地方的客户端签名不是为了数据安全,而是为了增加爬虫进行抓取的成本,因为一般网页爬虫都不具备 js 之行能力,这样就增加了它抓取的成本。
另外一点,签名虽然是由客户端签发的,但是却是由服务器端进行验证,我们这里是利用 JWT(JSON WEB TOKEN) 进行了 encode和decode过程,且通过将服务器时间对客户端进行下发,完成有效期控制。
起到一定的防DDOS攻击的效果
通过上图我们可以看到,关键就是两次票据的签发与验证,一次由浏览器签发,一次由后台签发,但是验证真伪都是在服务端进行,这样做的最终效果就是,要对我们的界面进行抓取或攻击的人,必须按照我们设定的套路运转,就会增加他下载js并执行我们js的过程,如果有攻击方利用xss 获的肉机,对我们的域名发起攻击时,由于我们有两次票据验证,而去其中有一个票据的有效期时间很短,基本上不太可能对我们的服务器造成连续伤害了。
如果网页抓取人,通过使用完全模拟浏览器的运行环境的第三方软件(PhantomJS、Selenium,WEBDRIVER)对我们进行抓取,其实效率是很慢的,基本上需要5-6秒完成一次, 基本上比一个真实的用户打开网页还要慢很多,对于这种可以当成是真是用户一样对待,数据本来就是开放的
接入这套反爬、防DDOS逻辑后,从模调系统查看数据后台服务被击穿的现象已经完成消失,异常流量已被隔离。
作者:STGOD
转载请标明出处:https://stgod.com/3396/