Google 是如何做负载均衡的?
Google 使用的技术一般都自带光环,吸引程序员的注意,基础设施方面的东西就更是如此,年初 Google 发布了篇论文介绍内部的负载均衡器的实现,让我们有机会一睹可能是全球最好的负载均衡器。
通常情况下的负载均衡要在灵活性和性能之间做权衡,用户态软件层面有 Haproxy 和 Nginx 这样的老牌负载均衡软件,他们一般配置和使用起来都比较容易,但是由于需要数据包从网卡到内核再到软件一层层向上处理,再一层层向下转发,堆栈比较深单机性能通常都比较一般。为了提高单机性能,减少堆栈层级就有了 Linux 里华人之光的 LVS,工作在内核层的负载均衡器,性能有着数量级的提高,然而配置起来相对也比较复杂而且对网络条件要求也有特殊要求。那 Google 有什么秘密的配方来达到高性能呢?
一般来说负载均衡器本身就是后端服务横向扩展的一个接入点,对于一般站点一个负载均衡器就够了,然而应对 Google 这种级别的流量,负载均衡器本身也要能横向扩展,还要处理负载均衡器的高可用,Google 又是如何做到的呢?
以我们访问 http://www.google.com 为例,第一步 DNS 服务器会根据请求的位置返回一个离请求地理位置最近的 VIP 地址,先在 DNS 这一层做一个横向扩展。接下来请求达到 VIP 对应的路由器,路由器通过 ECMP 协议,可以将请求平均分配到下面对等的多个负载均衡器上,这样在路由器这一层做了个负载均衡,让后面的负载均衡器也实现了横向扩展。再往下是一个类似于 LVS 中 DR 模式的分发,负载均衡器将请求包转发给服务器同时将源地址改为客户请求时的地址,服务器响应时将响应包的源地址改为 VIP 的地址直接打给路由器而不通过负载均衡器来降低负载均衡器压力。流程图如下
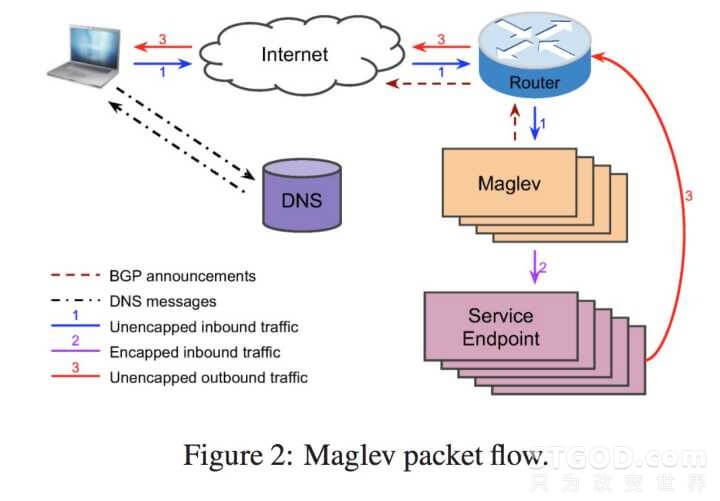
对了,Google 的这个负载均衡器叫 Maglev,磁悬浮列车的意思。自然是要做到极致的性能,只看流程似乎和 LVS 中 DR 模式很类似,但内部就完全不一样了。
简单的说虽然 LVS 已经做到 Linux 内核里了,但是在 Google 看来 Linux 是性能的瓶颈,到 LVS 之前还要经过完整的 TCP/IP 协议栈以及内核的一系列 filter 模块,而这些对于转发来说是没有必要的。于是 Google 的做法就是简单粗暴的绕过内核,把 Maglev 直接架在网卡上对接网卡的输入和输出队列,来一个数据包也不需要完整的 TCP/IP 协议栈的解析,进来的包只要分析前几个字节,拿出源地址,源端口,目标地址,目标端口和协议号这个五元组对于转发来说就已经足够了。剩下的诸如 payload,序列号之类的东西统统不关心直接塞到网卡输出口给后面就行了。
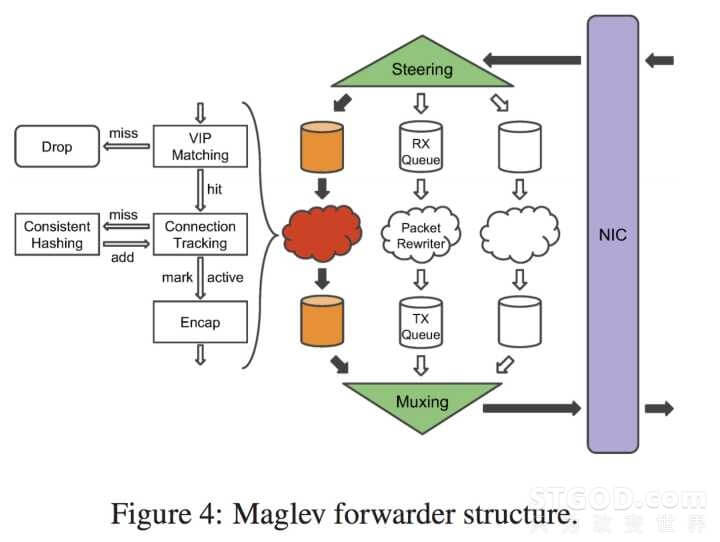
前几天听美团的介绍他们的负载均衡器是用的类似的思路用 DPDK 直接在网卡上编写应用,性能相对 LVS 就有数倍的提升。看 Maglev 的实现为了榨干性能是直接写在网卡上的,都没有 DPDK 之类的封装。绕过内核就可以自己分配内存管理内存就可以进一步的压榨性能。论文中可以看到 Maglev 是直接和网卡共享内存的,这样就不需要将数据包再从网卡进行一次复制到负载均衡器中,也不需要把数据包再从负载均衡器复制到网卡,网卡入口队列,负载均衡器,网卡出口队列共享一个数据池空间,三个指针不断的移动处理数据包,可谓是在内存这里做到了极致。

当然诸如 CPU 绑定,每个 CPU 专职处理一个线程来避免 cache miss,memory contention 这种常规优化也是都有的。最终的效果就是处理一个数据包平均需要 350ns,而性能发生抖动的情况一般是由于网卡发数据包是批量的或者要等待一个 timer 的中断,而这个中断的时间是 50us 所以当流量小的时候这个延迟可能会达到 50us。(我觉得 Google 这么写其实是在炫耀自己性能好,瓶颈在网卡刷新速度上,而不在负载均衡器上)
通常的负载均衡器都是一个单点,而 Maglev 是一个集群,集群就会碰到很多的问题。严格来说负载均衡器不能算是一个无状态的服务,因为 TCP 连接本身是有状态的,一组会话内的请求包必须转发到相同的后端服务器,不然服务器端的 TCP 会话就乱套了。对于单点的负载均衡器来说很好解决,记录个转发表里面有每个数据包的五元组和它第一转发到哪台机器,来一个新的数据包查这个表就知道给谁了。而像 Maglev 这样的集群数据包是通过路由器 ECMP 随机分发的,第一个数据包是这个 Maglev node 处理,下一个就不知道去哪个 Maglev node 了。而且集群就会涉及滚动式的更新和随机的故障,这样本机的转发表也就很可能会丢失。
之前听美团的介绍,他们的做法是在多台机器之间做内存的同步每次更新都要进行一次同步来保证所有机器转发表的一致。而 Google 一帮人不愧是搞研究出身的,直接就上了一致性哈希这个大杀器。这样的话可以直接通过五元组散列到后端的一台固定服务器,这样硬生生的把有状态服务做成了无状态,如此一来 Maglev 层面个就可以随意的更新,上线下线了。顺便的一个好处就是后端增加下线服务器都只会影响到当前这台机器所处理的连接不会造成所有连接的 rehash。当然只用一个普通的一致性哈希算法也没啥意思,Google 为了自己的需求专门写了个 Maglev Hashing
论文里还介绍了很多负载均衡器运维方面的经验以及设计的过程和经验,还说了下一些新的发展方向,感兴趣的可以关注下。
作者:STGOD
转载请标明出处:https://stgod.com/3909/