机器排序学习在电商搜索中的实战
背景
1号店的搜索Ranking Model一直在朝着精细化方向深化,我们希望在提升用户满意度的同时,也能提升网站的流量转化率。在实践机器排序学习之前,1号店网站的搜索Ranking Model已经经历了4个阶段:通用排序模型(Universal Ranking Model)、基于区域的排序模型(Region-based Ranking Model)、基于品类的排序模型(Category-based Ranking Model)和基于用户的排序模型(User-based Ranking Model)。
在这个过程中,需要对搜索、浏览、点击、购买,评论等几十个行为特征进行细粒度的分解和重组,这就需要人工去分析用户的搜索行为和流量效率之间的关系,并通过人工调整排序模型来优化效果。在细分了区域和品类之后,为了更有效地提升排序模型的优化效率,我们开始考虑使用机器排序学习算法。
机器排序学习的一般分为两个流程,其中“training data -> learning algorithm -> ranking model”是一个离线训练过程,包含数据清洗、特征抽取、模型训练和模型优化等环节。而“user query -> top-k retrieval -> ranking model -> results page”则是在线应用过程,表示利用离线训练得到的模型进行预估。
机器排序学习有如下优点:
- 人工规则排序是通过构造排序函数,并通过不断的实验确定最佳的参数组合,以此形成排序规则对搜索结果进行排序。但是在数据量较大、排序特征较多的情况下,依靠人工很难充分发现数据中隐藏的信息,而机器排序则可以较好地解决这个问题;
- 机器学习可以基于持续的数据反馈进行自我学习和迭代,不断地挖掘业务价值,对目标问题进行持续优化;
设计原则
从一开始,我们就没有考虑将机器排序学习作为人工规则排序的替代者,而是致力于将两者作为互为补充的排序模型,不同品类采用不同的排序策略,这也体现在了我们的搜索排序架构上。
图1表示目前1号店现在生产环境上机器排序学习的框架,包含两个部分:离线训练和在线应用。离线部分主要是根据历史数据以及训练目标,产生一个可用于在线预测的排序模型;而在线部分则是利用离线产生的排序模型,根据在线用户的Context完成实际的排序。
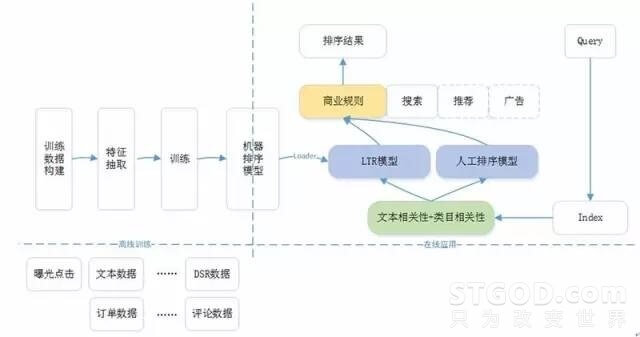
图 1 – 机器排序学习框架
在整个机器排序框架中,整个在线排序模块分为3层。
第一层称为一排(也称为粗排),主要是根据用户Query从索引库中召回所有相关商品,然后依据文本相关性和类目相关性得分,完成第1轮商品筛选,形成上层排序模型的候选商品集;
第二层称为二排(也称为精排),主要是以一排的候选商品集为基础,应用LTR模型或者人工排序模型,完成基于排序特征的重新排序;
第三层称为三排,主要是根据各种商业需求对二排的排序结果进行调整,如类目打散、商品推广等;
在整个机器排序框架中,离线部分需要模型评测环境,而在线部分更需要数据收集模块和A/B Test模块。这两点并没有在图1的框架中列出,但是在后续的介绍中会给出相应的说明。
机器排序学习离线训练过程
我们选择开源的RankLib[2]作为机器排序学习的工具包。在离线训练过程中,我们测试了RankNet, LambdaMART和Random Forests,根据评测结果,我们选择了LambdaMART(具体采用哪种模型,需要根据实际业务场景和训练结果而定)。该算法是一种有监督学习(Supervised Learning)的迭代决策回归树排序算法,目前已经被广泛应用到数据挖掘的诸多领域。
LambdaMART模型可以分成Lambda和MART两部分,底层模型训练用的是MART(Multiple Additive Regression Tree),也叫GBDT(Gradient Boosting Decision Tree),它的核心是每一棵树学习的是之前所有树结论和的残差,这个残差+当前的预测值就能得到真实值。而Lambda是MART求解过程使用的梯度,其物理含义是一个待排序的文档下一次迭代应该排序的方向和强度。具体LambdaMART的算法和工作原理可以参考[4]。
下面我们以LambdaMART为基础算法来介绍机器排序学习的整个过程。
3.1 训练目标数据
离线训练目标数据的获取有2种方法,人工标注和点击日志。两者都是为了构建出<q, p, r-score>的数值pair对,作为机器学习的训练数据集。这里q表示用户的查询query,p表示通过q召回的商品product,r-score表示商品p在查询q条件下的相关性得分。
其中人工标注一般步骤为,根据给定的query商品对, 判断商品和query是否相关,以及相关强度。该强度值可以用数值序列来表示,常见的是用5档评分,如1-差,2-一般,3-好,4-优秀,5-完美。人工标注一方面是标注者的主观判断,会受标注者背景、爱好等因素的影响,另一方面,实际查询的query和相关商品数量比较多,所以全部靠人工标注工作量大,一般很少采用。
因此,在我们的实践探索中,寻找获取方便且具有代表性的相关性的度量指标则成为重中之重。经过初期的探索,我们确定以CTR为基础,实现了低成本的query-product相关性标注(虽然不完美,但在实际工程中切实可行)。具体步骤如下:从用户真实的搜索和点击日志中,挖掘出同一个query下,商品的排序位置以及在这个位置上的点击数,如query_1有3个排好序的商品a, b和c,但是b得到了更多的点击,那么b的相关性可能好于a。点击数据隐式地反映了相同query下搜索结果相关性的好坏。
在搭建相关性数据的过程中,需要避免“展示位置偏见”position bias现象,即在搜索结果中,排序靠前的结果被点击的概率会大于排序靠后的结果;在我们的训练模型中,如图2所示,第6位开始的商品点击数相比前5位有明显的下降,所以我们会直接去除搜索结果前5个商品的点击数[5]。
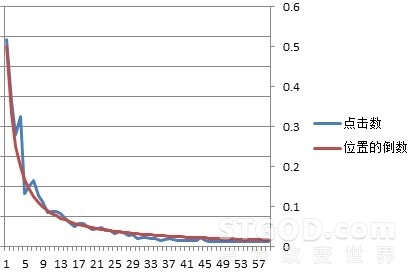
图 2 – 位置偏见的示意图
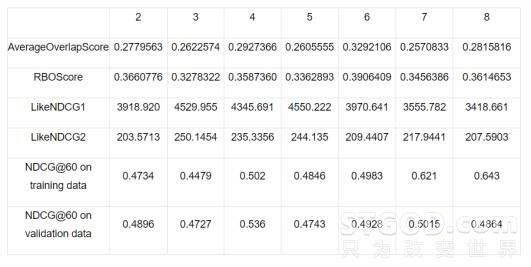
同时在实际场景中,搜索日志也通常含有噪音,只有足够多的点击次数才能体现商品相关性的大小。因此为了提升训练效率和训练效果,我们也针对Click数少于某个阈值的情况(即少于某个阈值的点击,我们就直接忽略)进行了测试,分别为2,3,4,5,6,7,8。经过离线分析,在阈值为4的情况下,NDCG分别有20%-30%的提升(这是NDCG@60 on validation data和当前线上的NDCG相比),效果提升比较明显。
表格 1 – Click数对训练目标的影响
3.2 特征抽取
LTR使用的排序特征(也称为Feature),和人工规则排序使用的特征基本相同。按照数据特性的差异,我们将其分为2大类,如表1所示,当然不同类型的数据价值和反映用户意图的强弱也不尽相同。
表格 2 – 特征抽取部分样例

特征数据分几类或者怎么分类都不是重要问题,这里主要是说明要尽可能抽取多的特征数据,供后续训练使用。同时对于机器排序学习而言,这里的行为特征都需要跟踪到Query维度,所以在数据采集的时候,需要预先处理好,这样才能体现Query对应的排序影响。如果能将订单特征也区分到Query维度会更好,但是我们现在还没有做到这一点,以后还会继续实验。
除了商品静态特征以外,商品动态特征、订单特征、行为特征、售后特征、商家服务特征都需要细分到品类和区域,幸运的是,在人工规则的排序模型阶段,就已经为我们准备好了profile-based的特征数据。为了能在人工规则排序和机器排序学习之间共享这些特征数据,我们将这些特征数据存储在基于HBase的Item Feature Repository数据库中。目前这些特征数据还是以天为单位进行批处理,而非实时完成。
在得到相关度数据和特征数据后,就可以根据LambdaMART训练数据的格式(如下所示),构建完整的训练数据集。每一行代表一个训练数据,项与项之间用空格分隔,其中<target>是相关性得分,<qid>是每个query的序号,<feature>是特征项的编号,<value>是对应特征项归一化后的数值,<info> 是注释项,不影响训练结果。
<target> qid:<qid> <feature>:<value> <feature>:<value> … <feature>:<value> # <info>
图3表示项目中使用的实际训练数据(这里选取了其中10个特征作为示例,#后面可以增加Query和商品名称,方便分析时的查看):
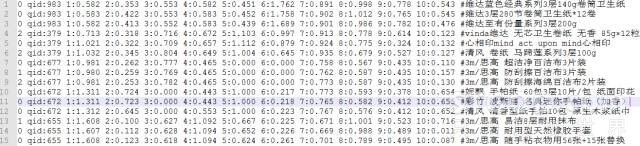
图 3 – LambdaMART训练样本
3.3离线训练
LambdaMART学习过程的主要步骤可以参考[4],数学推导不是本文的重点:
- 先遍历所有的训练数据,计算每个pair互换位置导致的指标变化deltaNDCG以及lambda;
- 创建回归树拟合第一步生成的lambda,生成一颗叶子节点数为L的回归树;
- 对这棵树的每个叶子节点通过预测的regression lambda计算每个叶子节点的输出值;
- 更新模型,将当前学习到的回归树加到已有的模型中,用学习率shrinkage系数做regularization;

图 4 – LambdaMART训练过程
RankLib提供了简单的命令行,只需根据实际的需要配置好参数,就可以实现训练模型、保存模型的功能。下面是我们在工程中使用的参数配置示例:
java -jar ~/bin/RankLib.jar -train ~/train_all.csv -gmax 4 -tvs 0.8 -norm zscore -ranker 6 -metric2t NDCG@60 -tree 1000 -leaf 10 -shrinkage 0.1 -save ~/models/learned_lambdamart_model.mod
参数说明
-train是必须的,表示训练样本所在的文件名;
-ranker是必须的,表示指定的机器学习算法,而6就是LambdaMART;
-gmax是可选的,指定训练目标相关性的最大等级,默认是4,代表5档评分,即{0,1,2,3,4};
-tvs是可选的,设置样本中用于训练的数据比例,即train数据:validation的比是0.8:0.2;
-norm是可选的,指定特征归一化的方法,默认没有归一化,zscore代表采用均方误差来归一化;
-metric2t是可选的,训练数据的评测方法,默认是ERR@10;
-tree是可选的,指定lambdamart使用的树的数目,默认是1000;
-leaf是可选的,指定lambdamart每棵树的叶节点数,默认是10;
-shrinkage是可选的,指定lambdamart的学习率,默认是0.1;
-save是可选的,用于保存模型;
上述命令执行结束后会在-save指定的目录下产生一个如图6的模型文件,该模型文件也就是可以用于生产环境的机器排序模型。
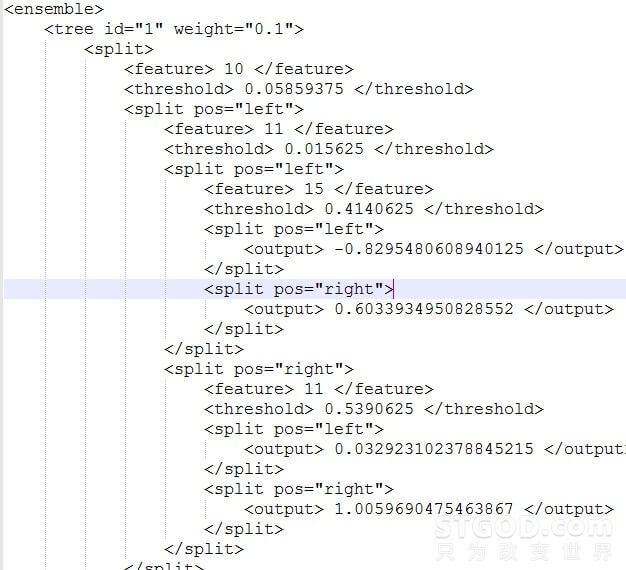
图 5 – LambdaMART训练产生的模型
3.4 离线评测
在排序模型训练完成之后,我们需要准备与训练样本相同数据格式的离线测试样本,这个测试样本尽量选取和训练样本不同的数据集。
java -jar ~/bin/RankLib.jar -load ~/models/learned_lambdamart_model.mod -test ~/test_samples.csv -metric2T NDCG@60 -score ~/rerank_scores.txt
这里-load对应的参数就是在离线训练中得到的排序模型,-test对应的参数就是测试样本集,-metric2T使用和训练过程相同的评价方式,-score对应的参数就是保存测试样本集中每个query下商品的得分。
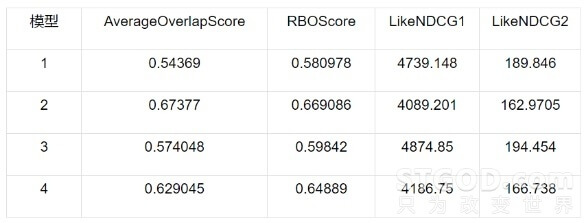
【实验样本】为了离线测试LTR的模型效果,选择了两个流量差异较大的类目,暂且称为类目A和类目B,其中类目A的流量大约是类目B的40倍。同时选择不同平台、不同时间段内的数据作为训练样本。
【评测指标】除了使用评价排序效果的NDCG以外,出于商业因素的考虑,我们还选择了4个评价排序位置变动情况的指标,其中AverageOverlapScore和RBOScore指标越大表示正常排序和LTR排序越接近,LikeNDCG1和LikeNDCG2指标越小表示正常排序和LTR排序越接近。
表格 3 – 类目A的离线评测效果
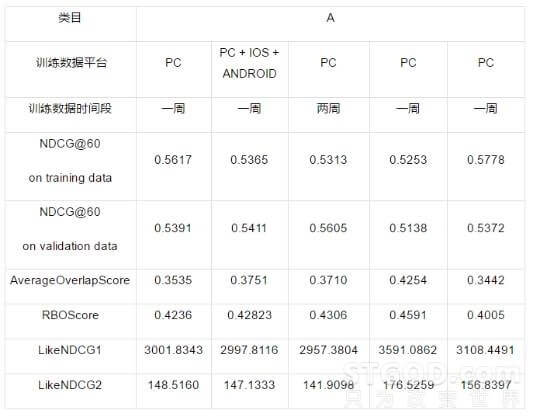
表格 4 – 类目B的离线评测效果

可以看出,同样用一周的数据,PC+IOS+Android的评测效果在多个指标上要好于只用PC的效果;而同样在PC端,两周数据的评测效果也好于一周;但是这个结论并不是普遍性,对于不同类目,需要具体问题具体分析,进而确定表现较好的模型。
另外,为了验证LambdaMART的不同训练参数对预测效率和预测效果的差异,我们也进行了其它4组实验,分别是如下:
- 默认参数设置
- 在1的基础上调整tvs参数
- 在2的基础上调整leaf参数
- 在3的基础上调整tree和shrinkage参数
4个模型的排序结果如下图所示,其中横坐标PO1表示线上排序1-8,PO2表示线上排序9-16,纵坐标表示这8个位置与LTR排序下商品位置变动数量。
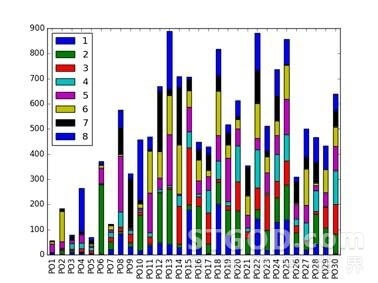
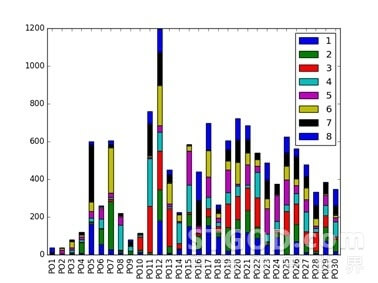
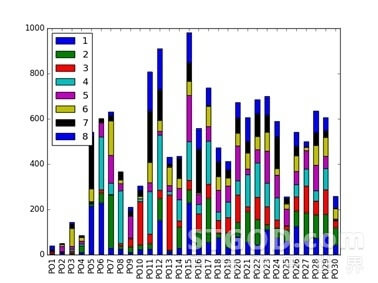
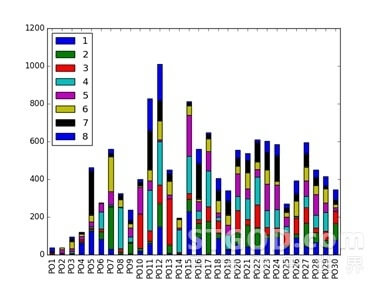
不同模型的指标对比如下,模型2的4个指标均为最佳。
表格 5 – 不同训练参数对训练结果的影响
综合LambdaMART在Training Data和Validation Data的迭代次数和训练时间来看,随着参数的增加,训练时间和迭代次数都有增加;但是当去除噪音Click的数据后,训练时间和迭代次数有明显的降低。
在线应用
【模型加载】离线测评时,可以用命令行的方式加载模型,读取数据文件,进而测试模型性能。显然这种方式并不适合在线应用,因此我们需要提取RankLib加载模型和在线打分的代码。为了有效进行系统地管理,我们将模型文件统一存放在MySQL表中,并利用字段区分类目和平台等信息。
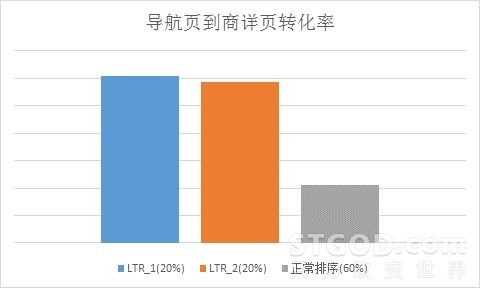
【在线测试】为了排除用户固有行为特性的影响,从而更加准确地比较LTR排序和人工排序的各项指标,在进行A/B Test之前,我们首先进行了一段时间的AA测试,从而选出各项指标较为接近的桶,再比较这些桶在LTR排序和人工排序之间差异。
将训练后的LTR模型按照图2的框架应用到生产环境中,在整个测试期间,我们观察了不同时间周期、不同平台数据产生的多个模型。总体来讲,LTR模型对“搜索导航页到商详页的CTR”在2016年11.11活动期间有约8.7%的提升,并且“订单转化率”在11.11活动期间有约4.5%的提升。(其中LTR_1和LTR_2是我们设置的不同流量分桶,用于观测不同分桶对模型的影响)
总结
总的来说,人工规则与机器排序是紧密结合的。如果排序的量化目标不太明确,则人工规则就更适合。电商搜索不仅要考虑查询相关性,还要考虑销售额和订单转化率,因此电商搜索往往有较多的业务规则。如eBay和Google在搜索排序方面就结合了人工业务规则,而广告排序一般更依赖于机器排序,因为其优化目标比较明确。所以我们也会在当前成果的的基础上,将机器排序学习进一步应用到推荐和广告系统上。
参考文献
[1] https://en.wikipedia.org/wiki/Learning_to_rank
[2] https://sourceforge.net/p/lemur/wiki/RankLib/
[3]http://jmlr.org/proceedings/papers/v14/burges11a/burges11a.pdf
[4] http://research.microsoft.com/en-us/um/people/cburges/tech_reports/msr-tr-2010-82.pdf
[5] An experimental comparison of click position-bias models. In Proceedings of the 2008 International Conference on Web Search and Data Mining (pp. 87-94). ACM
[6] https://class.coursera.org/ml-003/lecture/21
作者:STGOD
转载请标明出处:https://stgod.com/2925/