很多朋友想知道神策分析是如何实现在每天十亿级别数据的情况下能做到秒级导入和秒级查询,以及如何做到不需要预先指定指标和维度就能实现多维查询的。今天借此分享的机会,和大家交流一下我们的技术选型与具体的架构实现,希望能够对大家有所启发。
当然,脱离客户需求谈产品设计,不太现实;而脱离产品设计,纯粹谈技术选型与架构实现,也不现实。因此,我们首先会简要概述:
- 神策分析的产品定位和客户需求;
- 从系统的整体架构出发,逐步介绍每一个模块和子系统的具体实现。
根据客户的需求,我们在产品设计以及由之而来的技术选型上,上主要考虑了以下几点:
- 可以私有化部署,因此需要在设计上考虑运维、审计与权限的问题;
- 数据和处理能力都完全向客户开放,因此技术选型应以开源方案为主,便于复用和客户二次开发;
- 需要满足不同行业不同类型产品的需求,因此数据模型试图尽量简洁,以减少 ETL 代价;
- 能够满足不同规模客户的需要,因此能够最大支持每天十亿级别数据量;
- 能够满足客户对于刚刚发生行为的分析需求,因此需要能够做到秒级导入;
- 能够满足客户的自助式数据驱动,因此需要做到大部分查询秒级响应;
- 用户行为明细数据需要为客户积累作为数据资产,同时,从分析灵活性上,又需要能够做到不需要预先自定义指标和维度,因此采用 ROLAP 而不是 MOLAP 的方案。
那么,下面就让我们进一步来看看,在这些技术决策之下,我们具体是怎么实现的。
通常情况下,一个常见的数据平台,整个数据处理的过程,可以分为如下 5 步:
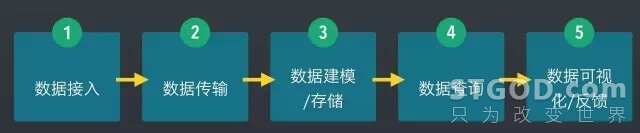
我们在设计上也基本遵循这一原则。下图是架构图:
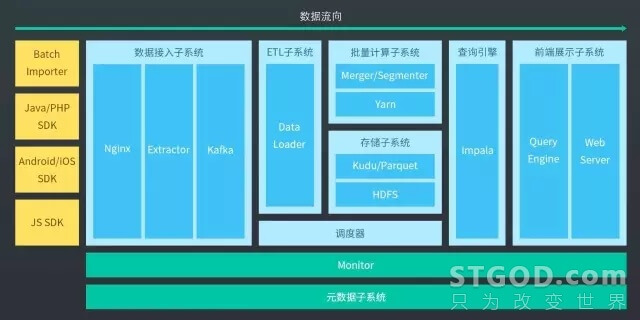
后面依次介绍各个子系统的具体技术实现。
我们主要支持采集三类数据,分别是前端操作、后端日志和业务数据。
1)采集前端操作
其中前端操作,主要是用户在客户端,如 iOS App、安卓 App 和网页上的一些操作,目前主流有三种采集方案,分别是全埋点、可视化埋点和代码埋点。
其中,全埋点是指默认地不加区分地采集所有能够采集的控件操作和交互,然后再在后端筛选出需要的数据;可视化埋点则是通过可视化交互的方式,提前选择要采集哪些控件的操作,然后再在操作发生时向后端发送数据;代码埋点则是最传统和广泛使用的一种技术采集手段,是以代码调用 SDK 接口的方式,来发送要采集的用户操作。
三种采集方式,在使用上,全埋点最简单,只需要嵌入 SDK 即可,但是会带来额外的数据开销;可视化埋点不会有额外的数据开销,嵌入 SDK 后需要用可视化的方式进行控件的点选。由于国内 App 开发普遍存在不遵循开发规范的情况,导致上述两种采集方案都存在一定的兼容性问题。代码埋点则是每一个点都需要一行或者更多的代码,更新迭代时使用较为复杂。
但是反过来,代码埋点却是采集能力最强的一种采集手段。我们以用户在京东的提交订单页面,来分别描述三者在采集能力上的差异:

在这个界面上,使用三种采集方案的采集能力大概如下面所描述的那样:
- 使用全埋点,可以知道某时某刻某人点击了某个按钮;
- 使用可视化埋点,可以跟进一步知道某时某刻某人提交了一个订单;
- 使用代码埋点,则可以更进一步地获取订单金额、商品名称、用户级别等自定义属性。
为了方便客户的使用,我们对于采集前端操作提供的方案则是:
- 以代码埋点为主,提供了 iOS、安卓和 JS 三种 SDK,特别是针对混合开发的 App,专门提供了原生 App 和 H5 之前交换数据,打通用户 ID 的接口;
- 以可视化埋点为辅,并且努力解决国内 App 的兼容性问题;
- 对于一些例如页面浏览、App 启动、App 进入后台等默认事件,则提供全埋点的方案,可以嵌入 SDK 之后直接采集;
- 建议客户根据不同的使用场景,选择最合适的前端埋点方案。
同时,为了最大限度保证嵌入了我们 SDK 的客户 App 的用户体验,我们专门针对 SDK 的数据发送策略做了很多优化,包括:
- 数据首先缓存在本地,达到一定规模或间隔时才发送;
- 仅在 3G/4G/Wi-Fi 时发送数据,发送时会对数据进行打包、压缩;
- 在产生首条数据、进入后台、退出程序时都会尝试发送,以尽可能兼容那些安装了 App 简单尝试后就快速删除的用户;
- 提供了强制发送接口,也让客户自己可以控制发送策略。
后端日志主要指产品的服务端模块在运行时打印出的日志。相比采集前端操作,采集后端日志会有如下一系列的优势:
- 传输时效性:如前面描述的那样,为了保证用户体验,前端采集数据是不能实时向后端发送的,所以会带来传输时效性的问题,而采集后端日志就不存在这个问题;
- 数据可靠性:前端采集需要通过公网进行数据传输,肯定会存在数据可靠性的问题,采集后端日志配合私有部署,则可以做到纯内网传输数据,这一问题大大缓解;
- 能够获取的信息丰富程度:有很多信息,例如商品库存、商品成本、用户风险级别、用户潜在价值等,在前端都采集不到的,只能在后端采集。
正因为这一点,我们建议一个行为在前端和后端都可以采集时,优先在后端进行采集,并且为此提供了一系列的后端语言 SDK、日志采集工具和数据批量导入工具等。
业务数据主要指一些供销存数据库数据、从第三方系统拿到的订单配送数据和客户数据等,针对这一类数据,我们提供了相应的数据导入工具,以及 RESTful 风格的导入 API,用于完成数据的导入。
对于前面三类不同的数据源,我们期望能够打通同一个用户在这三类数据源中的行为,并且为此提供了如下的技术手段:
- 不同端可以自定义唯一的用户 ID,如设备 ID、Cookie ID、注册 ID等,客户可以自己定义自己选择;当然,神策分析系统内部会有唯一的 user_id;
- 提供一次性的 track_signup 接口,将两个 ID 贯通起来,例如,可以将一个用户在浏览器上的 Cookie ID 与他在产品里面的注册 ID 贯通起来,然后这个用户以注册 ID 在手机 App 上登录时,我们依然能知道是同一个用户;
- 我们目前采用的方案不需要回溯数据,但是应用是有限制的,即只能支持一对一的 ID-Mapping,这也是一个典型的功能与性能的折衷。
不管是采用哪种采集方式,数据都是通过 HTTP API 发送给系统的。
而在数据接入子系统部分,我们采用了 Nginx 来接收通过 API 发送的数据,并且将之写到日志文件上。使用 Nginx 主要是考虑到它的高可靠性与高可扩展性,并且在我们的应用场景下, Nginx 单机可以轻松地做到每秒接收 1 万条请求,考虑到一条请求通常都不止一条用户行为,可以认为很轻松就能做到数万 TPS。
对于 Nginx 打印到文件的日志,会由我们自己开发的 Extractor 模块来实时读取和处理 Nginx 日志,并将处理结果发布到 Kafka 中。在这个过程中,Extractor 模块还会进行数据格式的校验,属性类型的识别与相关元数据的操作。与 ID-Mapping 的处理也是在这个阶段完成的。一些字段的解析和扩展工作,如基于 IP 判断国家、省份、城市,基于 UserAgent 判断浏览器、操作系统等,也是在这个阶段完成的。前面提到了,我们不需要用户预先指定指标和维度,基本实现了 schema-free,就是在 Extractor 处理阶段,对这些列进行校验,并且完成相关的元数据操作。
Kafka 是一个广泛使用的高可用的分布式消息队列,作为数据接入与数据处理两个流程之间的缓冲,同时也作为近期数据的一个备份。另外,这个阶段也对外提供访问 API,客户可以直接从 Kafka 中将数据引走,进入自己的实时计算流。
在介绍数据导入模块与数据存储模块之前,我们需要先讨论一下神策分析的数据模型设计。
前面已经提到,我们主要解决的是用户行为分析这么一个特定领域的数据分析需求,并且期望尽量简化数据模型以降低 ETL 代价。最终,我们选择了业内非常流行的 Event + User 模型,可以覆盖客户的绝大部分分析需求,并且对于采集到的数据不需要有太多的 ETL 工作。
Event 主要是描述用户做了什么事情。每一条 Event 数据对应用户的一次事件,由 用户 ID、Event 名称、自定义属性三部分组成。Event 名称主要是对 Event 的一个分类,例如“PageView”、“Search”、“PayOrder”等等。我们在客户端会默认采集设备 ID 或者 Cookie ID 作为用户 ID,客户也可以自己设置一个合理的用户 ID。而我们最多可以支持一万个自定义属性,并且开发者并不需要事先告之系统,系统会自动从接收的数据中解析发现新的字段并且进行相应的处理。
Event 数据以追加为主,不可修改,这也符合事件这一概念的实际物理意义。不过,为了方便后续系统的运维以及客户的使用,我们特别为 Event 数据提供了有限的数据删除能力,这一点会在后续存储部分更详尽地描述。
User 则主要描述用户是个什么样的人。它由用户 ID 与自定义属性两部分组成。自定义属性是年龄、所在地、Tag等。在神策分析中,它的来源主要有三类,一类是使用者自己采集并且通过接口告之系统的,例如用户的注册信息;一类是基于使用者的第一方数据挖掘得到的用户画像数据;还有一类则是通过第三方供应商得到的用户在第三方行为所体现出来的属性和特质。在神策分析中,User 数据是每一行对应一个用户,并且可以任意修改的。
正如前面所说,由于自身的产品需求,如导入时效性、不需要预先指定指标和维度等,目前比较热的开源 OLAP 系统如 Apache Kylin 和 Druid,我们并不能拿来使用。而最后,我们选择的是存储最细粒度数据,在每次查询时都从最细粒度数据开始使用 Impala 进行聚合和计算,而为了实现秒级查询,我们在存储部分做了很多优化,尽可能减少需要扫描的数据量以便加快数据的查询速度。
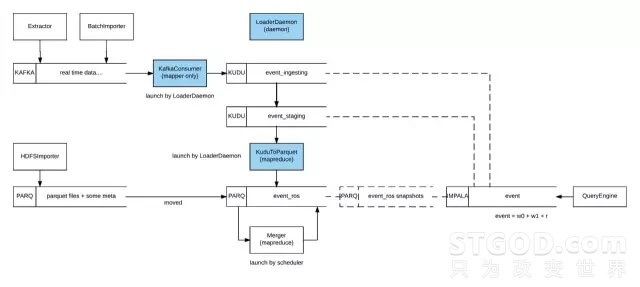
具体来说,虽然存储都是构建在 HDFS 之上,但是为了满足秒级导入和秒级查询,我们将存储分为 WOS(Write Optimized Store)和 ROS(Read Optimized Store)两部分,分别为写入和读取进行优化,并且 WOS 中的数据会逐渐转入 ROS 之中。
对于 ROS,我们选择了 Parquet,这样一个面向分析型业务的列式存储格式。并且,根据我们面临的业务的具体查询需求,对数据的分区方式做了很细致的优化。首先,我们是按照事件发生的日期和事件的名称,对数据做 Partition;同一个 Partition 内,会有多个文件,文件大小尽量保持在 512 MB 左右;每个文件内部先按照 userid 的 hash 有序,再按照 userid 有序,最后则按照事件发生的时间有序;会有一个单独的索引文件记录每个 user_id 对应数据的文件 offset。另外,与大多数列式存储一样,Parquet 对于不同类型的列,本身有着很好的压缩性能,也能大大减少扫描数据时的磁盘吞吐。简单来说,利用列式存储,只扫描必要的列,利用我们自己的数据分区方案,则在这个基础之上进一步只扫描需要的行,两者一起作用,共同减少需要扫描的数据量。
虽然 Parquet 是一个查询性能很好的列式存储,但是它是不能实时追加的,因此在 WOS 部分,我们选择了 Kudu。在向 Kudu 中写入数据时,我们选择了类似于 0/1 切换的方案,即同一时间只写入一张表,当这张表的写入达到阈值时,就写入新表中,而老表则会开始转为 Parquet 格式。
由于这样一个转换过程,不可避免地会带来 Parquet 的碎文件问题,因此也需要专门解决。
- KafkaConsumer:一个常驻内存的 MapReduce 程序 (只有 Mapper),负责实时从 Kafka 中订阅数据,并且写入到 Kudu 中。
- KuduToParquet:一个不定时启动的 MapReduce 程序,在 Kudu 单个表写入达到阈值并且不再被写入时,将它转成多个 Parquet 文件,并且移动到对应的 Partition 中。
- LoaderDemon:一个后台调度程序,完成一些元数据操作;
- Merger:一个定时的 MapReduce 任务,定期合并 Parquet 中每个 Partition 内的碎文件。
在数据查询部分,我们是通过 WebServer 这个模块,接收客户通过我们的 UI 界面或者通过 API 发起的查询请求,WebServer 并不做额外的处理,而是将这些查询请求直接转发给 QueryEngine 模块。QueryEngine 模块则是将查询请求翻译成 SQL,并在 Impala 中发起查询。Impala 会访问 Kudu 与 Parquet 数据共同构成的 View,完成对应的聚合与聚散。
特别提一下,在查询引擎部分,我们选择 Impala 而不是 Spark SQL,并不是出于性能或者稳定性的考虑,仅仅是因为我们团队之前有比较多的基于 Impala 的工作经验。
为了保证秒级的查询性能,我们除了在存储部分做文章以外,还在查询部分做了很多的优化,这些优化包括:
- 界面上提供的查询模型有限,但是能满足客户绝大部分需求,因此专门针对这些查询模型做有针对性的优化;
- 使用 UDF/UDAF/UDAnF 等聚合函数替代 Join,提高查询效率,特别一提的是,由于 Impala 不支持 UDAnF,这里我们修改了 Impala 的源代码;
- 比较精细的缓存,只对有变化的数据才进行重查;
- 提供按用户抽样的功能,客户可以通过抽样数据快速尝试不同的猜想,并最终在全量数据上获取准确结果。
我们主要使用 MySQL、ZooKeeper 来存储元数据,主要包括类似于 Schema、维度字典、数据概览、漏斗、分群、预测的配置、任务调度、权限等信息。我们还用到了 Redis 来存储查询缓存信息。
我们有 Monitor 这样一个常驻内存的模块,对系统的各个部分进行语义监控,并且进行异常状态的修复。当然,作为一个商业系统,我们对于 license 的处理也是放在这个模块之中的。
同时,为了减少运维的代价,对一些不常用的功能,虽然不提供界面但是也工具化了,包括数据清理工具、版本升级工具、性能分析工具、多项目管理工具等。
用户分群与用户行为预测,我们单独放在最后进行探讨。
我们对用户分群的定义,是根据用户以往的行为,给用户打标签。例如,找到那些“上个月有购买行为的用户”,“最近三个月有登录的用户”等。它是用户画像的一部分,但肯定不是用户画像的全部。
而与之相对的,用户行为预测则是根据用户过往的行为,预测将来做某个行为的概率。
这一部分的具体实现,我会在其它文章中做相应的介绍。