王者荣耀大数据运营总结
1. 整体框架
从数据开发的角度,此类运营项目主要会和策划同学、后台同学进行协作。前期工作主要是整理数据源、拆解数据指标,本文主要专注大数据计算过程,最后一步将结果同步给后台。框架如图所示。
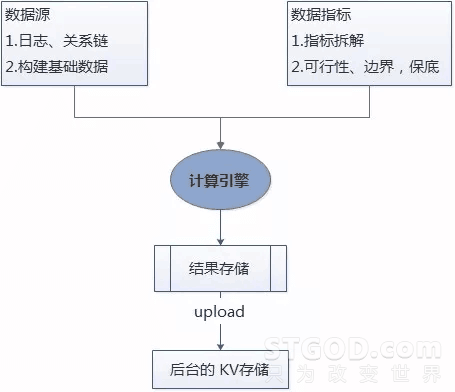
2. 计算引擎
计算引擎,可以选择的是:Hive-SQL 或者原生的Map/Reduce,如何抉择?我将列一下这两个方式的优劣对比,欢迎拍砖~
Hive-SQL
优势:
前期很爽,开发难度较低,快速上线。
劣势(后续迭代将是梦魇):
- SQL 实现复杂逻辑约束较多,局限了想象力。
- SQL 不能轻松地自定义函数、对象,重复地开发,代码冗长。
- 中间结果,无法复用。
- 增加/修改 指标,需要大幅度改动,后续的实现越来越困难。
- 调优的空间,较少。
原生Map/Reduce
优势:(Hive-SQL 的缺点,反过来就是,不再赘述。)
- RDD 复用,读入一次数据源,后面在内存中Cache、迭代计算。
劣势:
- 前期开发较慢,需要搭建较多的流程和抽象接口。
选型
- Spark 常用算子:map, filter, flatMap, reduceByKey, join 等。
- 编程语言 scala,语法简洁,函数式编程。
- 工程部署 Tesla 平台,可视化界面,便捷地增加数据依赖、调度、调参、查看日志。
3. 如何展开诸多数据指标?
数据指标纷繁复杂,主要的解决方案包括:1.优化好友关系链计算;2.分治法;3.封装求和计算;4.封装取最大/最小的指标;5.避免改变RDD的核心数据结构;6. 稳健地运行。面临大数据量时,希望1-2介绍的内容能提供读者一些启发;3-5 将不同类型的计算,分别封装,简化 reduceByKey的表达,代码也会比较简练。在解决常见问题时,第6点作为一个参考。接下来,见招拆招。
优化好友关系链计算
业务背景: 王者周报中,好友出现了游戏好友非微信好友,这种情况不太能接受。
对局日志和好友关系进行关联运算,判断是否开黑;计算了每个用户的基础指标后,关联好友关系,PK得到神奇好友。这里的瓶颈在于关联运算,数据集体量庞大,就像霸天虎和威震天发生了碰撞。先看一下 join 的源码:
// join 调用 cogroup,生成 (key, Tuple(list(v1,v2))),然后再做 flatMap。 /** * Return an RDD containing all pairs of elements with matching keys in `this` and `other`. Each * pair of elements will be returned as a (k, (v1, v2)) tuple, where (k, v1) is in `this` and * (k, v2) is in `other`. Uses the given Partitioner to partition the output RDD. */ def join[W](other: RDD[(K, W)], partitioner: Partitioner): RDD[(K, (V, W))] = self.withScope { this.cogroup(other, partitioner).flatMapValues( pair => for (v <- pair._1.iterator; w <- pair._2.iterator) yield (v, w) ) } /** * For each key k in `this` or `other`, return a resulting RDD that contains a tuple with the * list of values for that key in `this` as well as `other`. */ def cogroup[W](other: RDD[(K, W)], partitioner: Partitioner) : RDD[(K, (Iterable[V], Iterable[W]))] = self.withScope { if (partitioner.isInstanceOf[HashPartitioner] && keyClass.isArray) { throw new SparkException("HashPartitioner cannot partition array keys.") } val cg = new CoGroupedRDD[K](Seq(self, other), partitioner) cg.mapValues { case Array(vs, w1s) => (vs.asInstanceOf[Iterable[V]], w1s.asInstanceOf[Iterable[W]]) } }
关键的执行是 cg.mapValues,还有后面一步的 flatMapValues,运行的日志显示并行度和 other 关系紧密。当A join B 时,对 B 进行合理的 hashPartition,可以提升运行效率。经过测试, join算子性能强劲:不发生数据倾斜的前提,可以快速完成十亿级和十亿级的 RDD 进行关联。补充一点题外话,顺藤摸瓜看一下其他核心算子:distinct -> reduceByKey -> combineByKey。所以 Spark 的 distinct算子不会导致数据倾斜。
// distinct: 先将RDD 转为 Key-Value RDD,值为 null;然后调用 reduceByKey。 /** * Return a new RDD containing the distinct elements in this RDD. */ def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope { map(x => (x, null)).reduceByKey((x, y) => x, numPartitions).map(_._1) }
分治法
业务背景:周年庆,计算用户一年内的最高连胜、连败,一年内开黑最多的好友。
将一年的对局日志全部读入内存?考虑到王者的体量,打消了这个想法。分治法也许是突破口:先把每个月的对局日志合并计算,然后对12个月的中间结果再做一次合并。图示如下,每天的日志评估量级是2.5E,月活用户评估量级是1.2E,这个规模可以轻松应对。
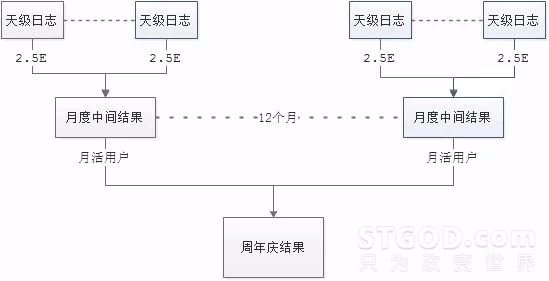
[ 分治法解决周年庆日志庞大的难点 ]
封装求和计算
从一个简单例子来,求玩家的对局数和胜场数。数据源加上了字段含义,实际的代码会更简洁 data: Rdd[(String, (Int, Int))]。
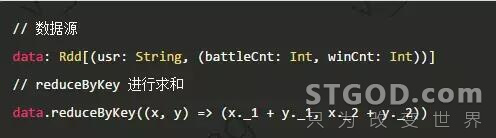
此次,x._1, x._2 可读性、维护性很糟糕,业务中有一些同学写了大量此类Magic 代码,异常头疼。王者周报超过50个数据项,开发过程中指标变化、增删都是常事,所以将用户的数据指标封装在 UsrSimpleInfo 类。示例如下。
class UsrSimpleInfo(mvp: Int, godlike: Int, three: Int, four: Int, five: Int, kill: Int, dead: Int, assist: Int, battle: Int) { val mvpCnt = mvp val godLikeCnt = godlike val threeKill = three val fourKill = four val fiveKill = five val killCnt = kill val deadCnt = dead val assistCnt = assist val battleCnt = battle override def toString = "UsrSimpleInfo: " + mvpCnt + "/" + threeKill + "/" + fourKill + "/" + fiveKill + "/" + killCnt + "/" + deadCnt + "/" + assistCnt + "/" + battleCnt def +(that: UsrSimpleInfo) = new UsrSimpleInfo( mvpCnt + that.mvpCnt, godLikeCnt + that.godLikeCnt, threeKill + that.threeKill, fourKill + that.fourKill, fiveKill + that.fiveKill, killCnt + that.killCnt, deadCnt + that.deadCnt, assistCnt + that.assistCnt, battleCnt + that.battleCnt ) def this() = this(0, 0, 0, 0, 0, 0, 0, 0, 0) }
reduce 的写法如下。
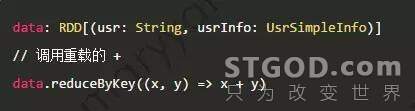
封装取最大/最小的指标
业务背景:1. 用户最常用英雄的表现,2. 在一段时间里,用户最新的游戏昵称。
用户在指标A 最大时的其他数据项, Hive-SQL 需要先求用户指标A的最大值,然后再join 原始表,实现方式比较笨重。
类似前面的做法,把上述逻辑进行对象封装和函数重载:

避免改变RDD的核心数据结构
业务背景:用户每个对局模式的对局场次,每个英雄的使用场次和表现。
粗暴方法如下。
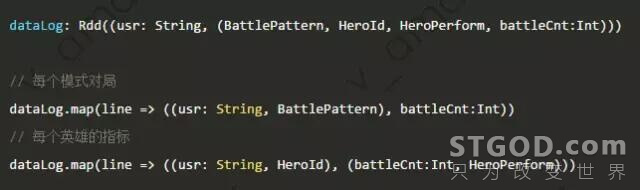
两个 map算子 都会对全量对局日志进行 transform,内存开销极大。Key-Value结构的RDD,修改Value是正常的,但是应该避免改变 Key。突破点在于:对局模式和英雄数枚举下来是比较少的,适合HashMap存储;最后reduceByKey 阶段做 Foldleft 合并数据。示例如下。

稳健地运行
产品发布之后,我发现“维稳”的压力很大。调试和运行的过程中,遇到了不少挑战。列举几个关键的节点。
- 入库日志校验和依赖。
- 运行监控。
Spark 任务的调度机制、内存分配,需要考虑多个影响因素。从 Spark UI 页面中,可以跟踪很多有价值的信息。任务根据 Action操作,划分到 Jobs,然后再进一步到 Stages。重点关注Stages阶段真实的执行顺序!Executors 显示了driver 节点和 data 节点的运行时信息。
- 超时告警和错误告警。
4. 提升效果
运行耗时其实不适合作为评估指标,仅做参考。不考虑分配的内存/CPU资源,还有计算集群负载,都是耍流氓。
下面写的运行耗时,不包含准备数据,强调的是目前计算花费的时间和日志吞吐量,应对产品运营节奏不再是瓶颈。上一节提到的方法,通常会综合应用、随机应变。
- 优化:
join算子调优;将面向过程的计算封装成对象;避免改变RDD的核心数据结构。 王者周报涉及十亿级别的上报日志(包括5v5、3v3、1v1对局、英雄熟练度等)和庞大的关系链,计算耗时2.5小时-3小时。 - 优化:将面向过程的计算封装成对象。 赛季总结的各项基础指标,只需要3-4小时完成。赛季结束的次日,通常可以体验/发布赛季总结。
- 优化: 分治法。 周年庆: 在王者荣耀用户体量和活跃度下,基于一年的对局日志计算了最大连胜、连败和开黑最多的好友。
- 优化:剪枝原始日志数据。 计算一个赛季的两两开黑情况,耗时50分钟。
5. 从产品角度解析王者数据运营
- 相比罗列数据指标,不如将数据包装成概念。数据不在于多、不在于奇,而在于“情”。

[ 左一成绩单罗列数据,新版包装成每周一字 ]
- 呈现用户个人的数据仅是初级层次,如何连接好友,需要更多的想象。
- 王者大数据运营,在资源转化、曝光用户数、游戏用户的渗透,分享量、来着分享的访问,以及最常规的拉新、拉回流分析上,都具有上佳的表现。
作者:STGOD
转载请标明出处:https://stgod.com/3935/