协程,是一种轻量级的用户态线程
简介:
协程(CoRoutine)是一种轻量级的用户态线程。简单来说,线程(thread)的调度是由操作系统负责,线程的睡眠、等待、唤醒的时机是由操作系统控制,开发者无法决定。使用协程,开发者可以自行控制程序切换的时机,可以在一个函数执行到一半的时候中断执行,让出CPU,在需要的时候再回到中断点继续执行。因为切换的时机是由开发者来决定的,就可以结合业务的需求来实现一些高级的特性。
协程的优点:
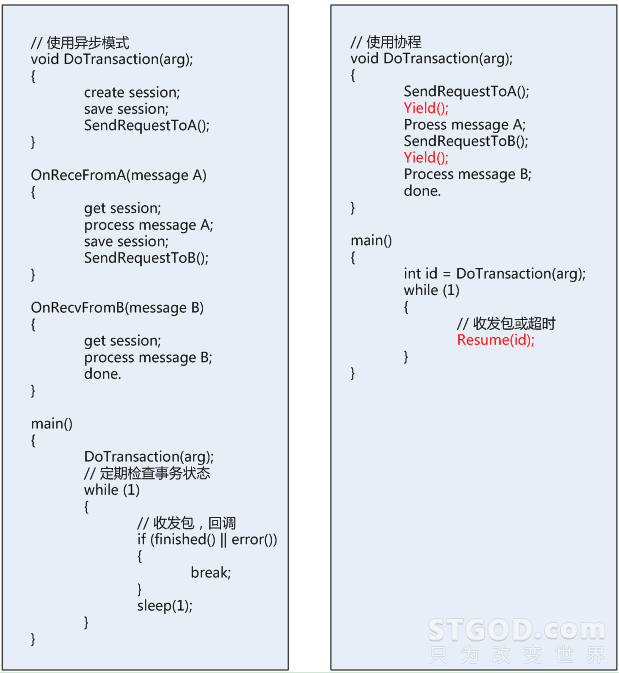
- 代码编辑简单。可以将异步处理逻辑代码用同步的方式编写,将多个异步操作集中到一个函数中完成,不需要维护过多的session数据或状态机,同时兼备异步的高效。
如果一个业务逻辑中涉及到多个异步请求,使用传统的异步回调方式,会使代码变得很凌乱,逻辑被不同的函数分享的支离破碎,非常不便于代码阅读。如果使用协程,可以将一个完整的业务逻辑集中在一个函数中完成,一眼了然。 - 编程简单。单线程模式,没有线程安全的问题,不需要加锁操作。
- 性能好。协程是用户态线程,切换更加高效。
举例:
一个事务需要AB三个步骤,每一步需要请求不同的服务器:
可以看到:如果使用协程的话,可以在一个函数中看到参数,每个步骤的请求和应答内容,就不需要用户再去维护一个session和状态机。并且,看起来就像同步一样的代码逻辑。
协程的语义:
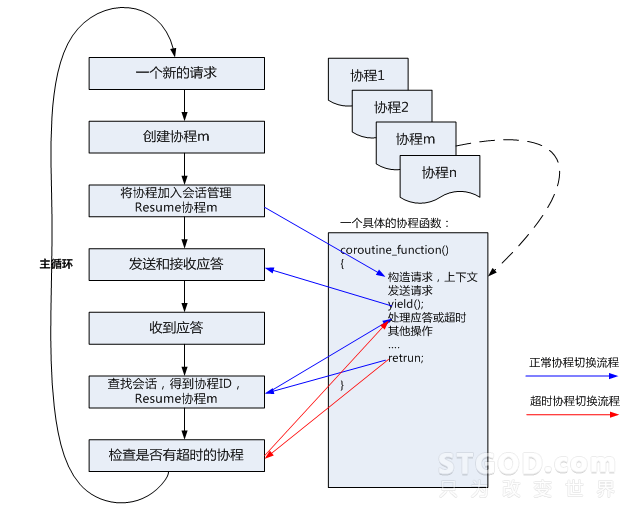
一般的协程实现都会提供两个重要的操作Yield和Resume。其中:
Yield:是让出cpu的意思,它会中断当前的执行,回到上一次Resume的地方
Resume:继续协程的运行。执行Resume后,回到上一次协程Yield的地方。
协程的使用:
在一个后台服务器框架中,协程创建和启动的时机非常重要。一般来说,会在收到一个请求包时认为是一个事务的开始,此时创建并启动协程,协程执行完即认为事务结束。期间,如果遇到异步请求事件,当发送完请求后,在协程内主动Yield,当收到应答后再Resume回来。其过程可以用下图表示:
C++协程的实现:
因为c++语言本身没有协程的功能,需要自行实现。Linux环境下常见的实现方式是使用setcontext/swapcontext。
协程的性能:
测试方法:
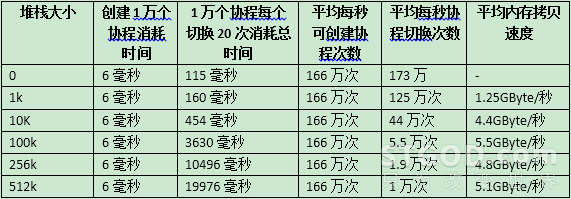
创建1万个协程,每个协程调度20次。一共测试5组,每组设置不同的堆栈大小。
测试结果:
结论:
1、协程的创建稳定,不受栈大小影响。
2、协程切换的性能:主要开销是在堆栈的拷贝(每次切换都需要备份栈),栈越大,切换耗时越多,接近内存拷贝的性能极限。
3、协程的内存资源占用:取决于堆栈的大小,如有1万个协程同时被调度,每个协程栈大小为1K,就需要100MByte的内存。
说明:
协程关于栈的管理有2种实现:
1、每个协程固定栈大小,创建协程的时候指定栈空间,切换的时候不用再备份栈。特点:性能好,但每个栈都是固定大小,占用内存较多。如每个栈设置4M,如果有1000个协程同时在跑,占用4G内存。
2、每个协程栈大小不固定,按实际需要分配,但是在切换的时候要备份栈。特点:节省内存,但当栈空间较大时,因为需要内存拷贝,性能差。
目前是按第2钟实现,主要是基于以下考虑:
1、栈的大小不好统一设定
2、对于一个server而言,瞬间同时处理的请求达到1000个左右是很正常的,如果有一个函数栈需要较多内存,则整个进程要求内存就会太多
3、大部分时候一个函数栈的空间是比较小的(10K以下)
协程的缺点:
1、在协程执行中不能有阻塞操作,否则整个线程被阻塞
2、有注意全局变量、指针的使用
结束语:
相当于协程的不足,将代码由异步变为同步,简化代码逻辑这个优势还是相当明显的。分布式开发框架pebble对协程进行了很好的封装和集成,大大降低了协程使用的难度。
作者:STGOD
转载请标明出处:https://stgod.com/3049/