从MySQL到Kafka,如何管理每天实时发布的几十亿条消息?

当你的系统每天要实时从MySQL到Kafka发布几十亿条消息时,你会怎么管理这些数据的模式信息呢?当你的系统要接入几百个服务时,你就要处理几千种不同的模式,手工管理是不可行的。必须有自动化的方案来处理从上游数据源到所有下游消费者的模式改变问题。Confluent公司的Schema Registry和Kafka Connect都是不错的选择,可惜当我们开始构建Yelp数据管道时它们还没发布。因此就有了我们的Schematizer。
Schematizer是什么?
Yelp数据管道的一个重要设计就是将所有数据都模式化,也就是说,所有流经数据管道的数据都必须遵守某种预先定义好的模式,而不是格式随意的。为什么非要强调这一点呢?因为我们想让所有的数据消费者都可以对他们要获取的数据格式有预期,因此可以在上游数据生产者决定改变他们发布的数据模式时,不会对下游造成非常大的影响。统一的模式表现也让Yelp数据管道可以轻松地整合各种使用不同数据格式的系统。
Schematizer是用于跟踪和管理所有数据管道中用到的模式,并且提供自动化文档支持等功能的模式存储服务。我们使用Apache Avro来表达模式。Avro有许多我们在数据管道中需要的功能,尤其是模式演进,它是解耦数据生产者和消费者的关键因素之一。每一条流经数据管道的消息都用Avro模式序列化过。为了减小消息体积,我们没有把全部模式信息都放在消息里,而只是带上了模式的ID。数据消费者可以用ID来在运行时从Schematizer中获取模式信息并将消息反序列化。Schematizer是所有预定义的模式信息的唯一可靠来源。
用不同方法管理模式
Schematizer用两种方法组织和管理模式:从数据生产者的角度和数据消费者的角度。
第一种方法根据数据的产生信息来将模式分组,每个组由名字空间和数据源来定义。生产者在向Schematizer注册模式时必须提供名字空间和数据源信息。比如一个准备向数据管道发布数据库数据的服务,它就可以把服务名作为名字空间,把表名作为数据源。

根据名字空间和数据源来将模式分组
第二种方法按数据的目的方信息来分组。比如Redshift集群或者MySQL数据库都是数据目的方,它们会对应一个或多个数据生产者,每个数据生产者又会关联一个或多个模式,这就对应着第一种方法中定义的名字空间和数据源。
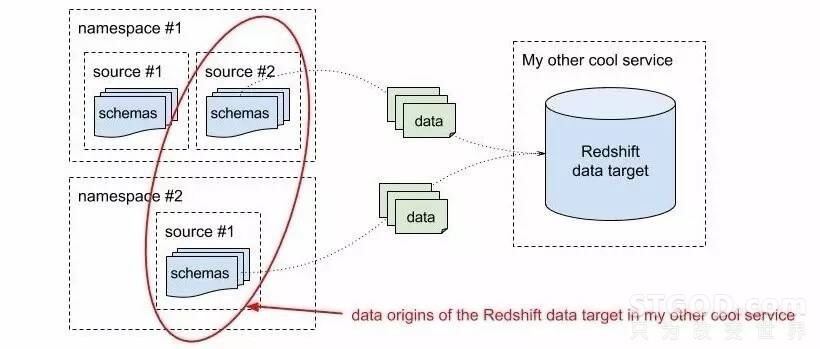
根据单个数据目的方来将模式分组
这两种方法让我们可以按不同的需要来检索和相关的模式。比如,一个程序可能想知道它会向哪些Topic发布数据,另一个服务又想知道它的Redshift集群中的数据都来自哪里。
注册模式
数据管道要求所有发布到其中的数据都必须用预定义的Avro模式进行模式化和序列化。因此,当一个数据生产者准备向数据管道发布数据时,它要做的第一件事就是向Schematizer注册模式,最通用的办法就是直接注册一个Avro模式。
对于没有或者无法创建Avro模式的数据生产者,也可以向Schematizer中加入模式转换器来把非Avro模式转换成Avro模式。MySQLStreamer就是一个代表,它是一个把MySQL数据库中的数据发布到数据管道的服务,它只知道MySQL表模式。Schematizer可以把MySQL表模式定义转换成相应的Avro模式。但如果数据生产者改变了模式定义的话,它必须重新注册。
上游模式改变会不会影响下游服务?
所有数据管道服务都不能回避的共同痛点就是该如何应对上游模式改变。通常这都需要许多在上游生产者和下游消费者之间的沟通和协调工作。Yelp也不能免俗。我们也有批量任务和系统,它们要处理别的批量任务和系统产生的数据。每一次上游的模式改变都是非常痛苦的,它可能导致下游服务崩溃,整个处理过程都是非常耗费人力的。
我们通过模式兼容性来解决这个问题。在模式注册过程中,Schematizer会根据模式兼容性来决定Topic和新模式之间的对应关系。只有兼容的模式才能延用旧的Topic。如果有不兼容模式注册上来,Schematizer会用相同的名字空间和数据源来为新模式注册一个新的Topic。那Schematizer又怎么确定兼容性呢?答案就是Avro解释规则(Avro resolution rules)。Avro解释规则保证在相同的Topic中,用新版模式打包的消息可以按旧版模式解包,反之亦然。

不兼容的模式会分配不同的Topic
目前Yelp数据管道中大部分数据都产生自MySQLStreamer。比如我们想为某业务表增加一个字段,MySQLStreamer就会向Schematizer注册新模式。因为按照Avro解释规则这样的改动是兼容的,所以Schematizer会创建新Avro模式,并把这个名字空间和数据源对应的旧的Topic分配给它。可如果是想把某字段从int改成varchar,那这就是一个不兼容的改动了,Schematizer会为新模式创建一个新Topic。
保证了在Topic内部的模式兼容性,下游数据消费者就可以放心的用旧模式去处理这个Topic中的任何数据,不必担心数据模式变化会引起自身的崩溃等任何问题。他们也可以根据自己的需要在合适的时候连上新Topic。这就让整个系统自动化程度更高,在模式改变时减少人工介入。
除了Avro解释规则,我们也在Schematizer中定义了一些自己的规则来支持一些数据管道功能。模式的主键字段被用于在数据管道中做日志压缩。因为对同一个Topic来说做日志压缩的主键必须保持一致,所以任何对主键的改动都被认为是不兼容的,会导致Schematizer为新模式创建一个新Topic。而且,当人工不可读(non-PII,Personally Identifiable Information)的模式开始包含人工可读字段时,这样的改动也被认为是不兼容的。人工不可读的数据和人工可读的数据必然分开存储,这样就简化了人工可读数据的安全实现,避免了下游消费者不小心读到一些他们本来没有权限读的数据。
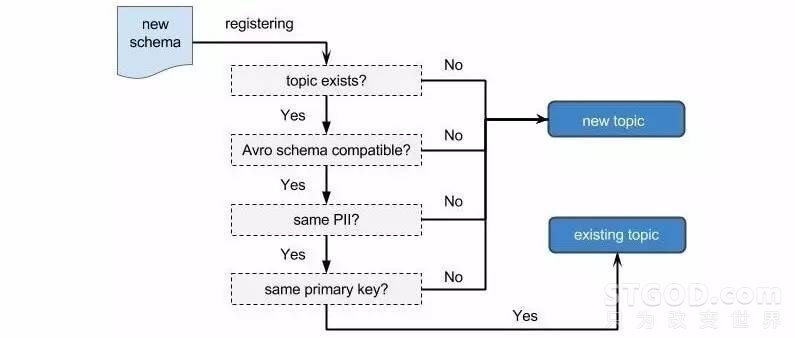
决定是否需要新Topic的逻辑流程
值得一提的是模式注册过程是幂等的。如果把相同的模式注册多次,那只有第一次会产生一个新模式,后面的都直接返回已注册的模式。这就让应用程序和服务可以非常容易地初始化它们的Avro模式。许多应用程序和服务都是把Avro模式定义在文件中或代码中的,但它们没办法写死模式ID,因为模式ID是由Schematizer管控的。所以应用程序可以调用模式注册接口来直接注册模式,如果已经存在就把模式信息取回来了,如果不存在就直接注册,一举两得。
将模式改变事件处理全部流水线化
为了让数据管道可以完全以流水线的方式处理模式改变事件,Schematizer会根据当前模式和新模式的信息来为下游系统生成模式迁移计划。目前Schematizer只能为Redshift表生成模式迁移计划。对于把数据从数据管道中应用到Redshift集群的下游系统来说,在模式发生改变时它可以直接获取模式迁移计划并且执行,而且自动获取新的模式信息,不需要任何人工介入。这个功能是很容易扩展的,而且模式迁移计划生成器也是很容易替换的,所以将来我们会增加更多的模式迁移计划生成器来支持更多的模式类型,或者改用更好的算法来生成迁移计划。
Schematizer知道所有数据生产者和消费者的信息
除了管理注册的模式,Schematizer还会跟进所有数据生产者和消费者的信息,包括哪个团队哪个服务负责生产或消费什么数据,发布数据的频率如何,等等。在需要人工介入时我们就可以用这些信息来有效地找到相应团队并与他们沟通协商。而且这些信息也可以帮助我们监控和找出那些过期了的模式和Topic,从而可以将它们做废或删除。这样,就可以在新模式注册上来时简化兼容性验证工作。Schematizer可以跳过那些废弃的模式,只检查新模式与Topic内剩下的有效的模式的兼容性就可以了。
所有数据生产者和消费者在启动时都必须提供这些信息。最初我们只想着把它们保存在Schematizer里就好了,但事实上这些信息对探索性的分析和预警都是非常有用的,最终我们决定把它们写到数据管道系统之外的单独的Kafka Topic中。这样数据就可以被Redshift和Splunk处理,也可以导入Schematizer和通过前端Web界面展示出来。我们用的是Yelp自行研发的通过Clog写入数据的异步、非阻塞式Kafka生产者,这样就不会影响生产者正常地发布数据。另外,这样也可以避免环形依赖,有时候正常的生产者要用相同的信息去注册多次。
该用哪个Kafka Topic呢?Schematizer会处理好这些细节
与一般意义上的Kafka生产者不同,数据管道的数据生产者不需要事先知道它们应该把数据发送到哪个Kafka Topic中。因为Schematizer规定了注册上来的模式和Topic之间的对应关系,所以数据生产者只要提供自己序列化数据所使用的模式信息,就可以从Schematizer那里得到正确的Topic信息并发布数据了。将Topic信息抽象出去可以让接口更简单易用。
对数据消费者也是类似的机制。尽管也可以给它们定下一些具体的Topic去消费,但更常见的用例是让Schematizer根据数据消费者感兴趣的组的信息来提供正确的Topic。在本文前面章节介绍了各种不同的分组机制。数据消费都可以或者指定名字空间和数据源,或者指定数据目的方,Schematizer就会找出那个组内的相应Topic。这种机制对于数据消费者感兴趣的一组Topic可能由于模式的不兼容改变而变来变去的场景尤其有效。它让数据消费者不必再跟踪组内的每一个Topic。
模式很好,文档更好!
模式把数据格式化了,但对于想了解数据确切意义的人来说提供的信息可能又不够。我们注意到使用数据的人通常不是生产数据的人,因此他们不知道去哪里找到有用的信息来让他们理解他们要用的数据。因为Schematizer负责管理数据管道中的所有模式,所以把数据的描述信息也保存在它这里就很合适。
知识挖掘器Watson隆重出场
Schematizer要求模式的注册方随着模式一起提供文档,然后Schematizer会提取文档信息并保存起来。为了让Yelp公司内的各个团队可以获得模式和数据文档,我们开发了Watson,一个全公司员工都可以用来挖掘数据内容的Webapp。Watson实际上是Schematizer的一个可视化前端,它通过Schematizer的几个RESTful API来获取数据。
Watson提供了关于数据管道状态的有价值信息:现有的名字空间、数据源及相关的Avro模式信息。最重要的是,Watson为查看Schematizer管理的所有数据源和模式信息提供了简单的方法。
文档并不是天上掉下来的
目前流经我们数据管道的数据主要都来自于数据库。我们用SQLAlchemy模型来为这些数据的数据源和模式整理文档。在Yelp,SQLAlchemy用来描述我们数据库中的所有模型。除了docstring之外,SQLAlchemy还允许用户为模型的字段增加额外信息。因此,它自然成了我们保存文档的首选之处,记录各个数据模型和字段的目的和意义。
SQLAlchemy还引入了一个属主字段来记录每个模型的维护者和专家。我们认为生成数据的人是提供文档的最佳人选。另外,这种方法也会鼓励大家时刻保持真实数据模型与描述的同步。
class BizModel(Base): __yelp_owner__ = Ownership( teams=[TEAM_OWNERS['biz_team'], members=[], contacts=[] ) __table_name__ = 'my_biz_table' __doc__ = 'Business information.' id = Column(Integer, primary_key=True, doc=r"""ID of the business.""") name = Column(String(64), doc=r"""Name of the business.""")
一个简单的包含文档和属主信息的SQLAlchemy模型
可是开发者在做SQLAlchemy模型的时候并不总是会记得提供文档信息。为了防止这样的事情发生,我们开发了自动校验功能来强制要求所有模型都必须完整地提供了属性描述和文档,这是绝不会退让的硬性标准。每当有新模型要加入时,如果要求的文档信息不完备,或者没有属主信息,校验就会失败。这些自动校验功能帮助我们朝着100%文档覆盖率的目标迈进了一大步。
为Watson提取高质量文档
当数据模型有了文档之后,我们就可以把它导入Schematizer并最终通过Watson展现出去。在深入具体提取流程之前,我们先介绍一下这个过程中的另一个重要模块:特定应用转换器(Application Specific Transformer),简写为AST。与名字含义一样,AST从一个或多个数据管道Topic中输入消息流,用转换逻辑处理消息模式和数据包,再把转换后的消息输出到另外的数据管道Topic中。提供具体转换处理的转换模块是可以串连起来的,因此可以组合多个模块来做非常细致的转换工作。
我们用AST中的许多个转换模块来依据SQLAlchemy模型生成更易理解的数据。因为模块是可以串连的,现在我们只是简单的创建一个从SQLAlchemy模型中提取文档和属主信息的转换模块,并把它加入到已有的转换链中。这样,所有模型的文档和属主信息就通过现有管道自动提取并导入Schematizer了。实现过程相当简单,并无缝接入管道,所以可以非常有效地生成高质量文档。

AST中的转换模块
如上所述,AST中现在已经有了一些为用户生成更有意义的信息的转换模块。位标志转换模块会解释一个整型字段的不同数据位的具体含义。相似地,Enum字段转换模块也会把Enum值转换成可读的文字表述。这些转换模块带来的另一个好处是它们同时也产生了自解释和自生成文档的模式,因此也产生了更好的文档。
合作、贡献与检索
开发者的文档并不是我们要讲述的最后一项内容。Watson也提供了功能让终端用户可以一起努力,为使Yelp的数据更具可读性而贡献自己的力量。
第一个功能就是打标签。Watson允许用户为任意数据源打标签分类。一个数据源可能是个MySQL数据库表,也可能是个数据模型。比如,一个业务数据源可以打上“Business Information”的标签,而一个用户信息数据源可以打上“User Information”标签。终端用户可以把相关的数据源都打上相同的标签,这样以对自己最有意义的方式把它们组织在一起。打标签可以让我们更深入的理解我们的各个数据源之间是如何彼此关联的。

打上了“Business Info”标签的业务数据源
Watson提供的另一个功能是添加注释。终端用户,尤其是非技术人员,可以通过这种方法来为一个数据源或字段提供他们自己的文档。比如业务分析师常常就会对使用数据有非常宝贵的见解,他们可以通过注释来分享各种疑难杂症、边界用例和时效性很强的信息。
终端用户对于Watson的最大的需求就是检索。我们在Watson中实现了简单的检索引擎,让用户可以检索数据的模式、Topic、数据模型描述等各方面信息。在检索后台我们没有用Elasticsearch,而是选择了Whoosh Python包,因为它可以帮助我们快速完成开发。就我们目前的检索量来说Whoosh的性能足以应付。随着数据规模增大,我们将来会考虑换用其它更易扩展的引擎。
结论
Schematizer是Yelp数据管道的一个重要组成部分。它的模式注册操作是数据管道的许多重要功能的基础,包括在上游数据生产者更改模式时减轻对下游消费者程序和服务的影响等。Schematizer也管理了数据发布的Topic分配,让用户不必再关心具体使用哪个Topic等这样的细节。最后,它要求所有写入数据管道的数据都必须有文档,这促进了全公司内的知识分享。Watson的加入更是使得Yelp公司内的所有员工都可以方便地得到最及时的信息。
我们已经细致了解了Schematizer和它的前端文档系统Watson。接下来,我们将细致分析流处理器:Paastorm。请大家继续保持关注!
这是关于Yelp的实时流数据基础设施系列文章的第三篇。这个系列会深度讲解我们如何用“确保只有一次”的方式把MySQL数据库中的改动实时地以流的方式传输出去,我们如何自动跟踪表模式变化,如何处理和转换流,以及最终如何把这些数据存储到Redshift或Salesforce之类的数据仓库中去。这一篇主要介绍Schematizer,Yelp的模式存储服务。
作者:STGOD
转载请标明出处:https://stgod.com/2956/