聊聊Greenplum的那些事

笔者有幸从04年就开始从事大规模数据计算的相关工作,08年作为Greenplum 早期员工加入Greenplum团队(当时的工牌是“005”,哈哈),记得当时看了一眼Greenplum的架构(嗯,就是现在大家耳熟能详的那个好多个X86框框的图),就义无反顾地加入了,转眼之间,已经到了第8个年头。
在诸多项目中我亲历了Greenplum在国内的生根发芽到高速发展,再到现在拥有一百多个企业级用户的过程。也见证了Greenplum从早期的2.1版本到当前的4.37版本,许多NB功能的不断增强、系统稳定性的不断大幅提高,在Greenplum的发展壮大中,IT行业也发生着巨大的变化,业界潮流沿着开放、开源的方向走向了大数据和云计算时代。由此看出,Greenplum十来年的快速发展不是偶然发生的,这与其在技术路线上始终保持与整个IT行业的技术演进高度一致密不可分的。

多年历练中接触过大大小小几十个数据类项目,有些浅尝辄止(最短的不到一周甚至还有远程支持),有些周期以年来计(长期出差现场、生不如死),客观来说, 每个项目都有其独一无二的的特点,只要有心,你总能在这个项目上学到些什么或有所领悟。我觉得把这些整理一下,用随笔的方式写下来,除了自己备忘以外,也许会对大家更深入地去了解GP带来一些启发,也或许在某个技术点上是你目前遇到的问题,如乱码怎么加载?异构数据库如何迁移?集群间如何高速复制数据?如何用C API扩展实现高效备份恢复等。希望我的这篇文章能够给大家带来帮助,同时也希望大家多拍砖。
Greenplum最早是在10多年前(大约在2002年)出现的,基本上和Hadoop是同一时期(Hadoop 约是2004年前后,早期的Nutch可追溯到2002年)。当时的背景是:
由此,业界认识到对于海量数据需要一种新的计算模式来支持,这种模式就是可以支持Scale-out横向扩展的分布式并行数据计算技术。
当时,开放的X86服务器技术已经能很好的支持商用,借助高速网络(当时是千兆以太网)组建的X86集群在整体上提供的计算能力已大幅高于传统SMP主机,并且成本很低,横向的扩展性还可带来系统良好的成长性。
问题来了,在X86集群上实现自动的并行计算,无论是后来的MapReduce计算框架还是MPP(海量并行处理)计算框架,最终还是需要软件来实现,Greenplum正是在这一背景下产生的,借助于分布式计算思想,Greenplum实现了基于数据库的分布式数据存储和并行计算(GoogleMapReduce实现的是基于文件的分布式数据存储和计算,我们过后会比较这两种方法的优劣性)。

话说当年Greenplum(当时还是一个Startup公司,创始人家门口有一棵青梅 ——greenplum,因此而得名)召集了十几位业界大咖(据说来自google、yahoo、ibm和TD),说干就干,花了1年多的时间完成最初的版本设计和开发,用软件实现了在开放X86平台上的分布式并行计算,不依赖于任何专有硬件,达到的性能却远远超过传统高昂的专有系统。
大家都知道Greenplum的数据库引擎层是基于著名的开源数据库Postgresql的(下面会分析为什么采用Postgresql,而不是mysql等等),但是Postgresql是单实例数据库,怎么能在多个X86服务器上运行多个实例且实现并行计算呢?为了这,Interconnnect大神器出现了。在那1年多的时间里,大拿们很大一部分精力都在不断的设计、优化、开发Interconnect这个核心软件组件。最终实现了对同一个集群中多个Postgresql实例的高效协同和并行计算,interconnect承载了并行查询计划生产和Dispatch分发(QD)、协调节点上QE执行器的并行工作、负责数据分布、Pipeline计算、镜像复制、健康探测等等诸多任务。
在Greenplum开源以前,据说一些厂商也有开发MPP数据库的打算,其中最难的部分就是在Interconnect上遇到了障碍,可见这项技术的关键性。
说到这,也许有同学会问,为什么Greenplum 要基于Postgresql? 这个问题大致引申出两个问题:
1、为什么不从数据库底层进行重新设计研发?
道理比较简单,所谓术业有专攻,就像制造跑车的不会亲自生产车轮一样,我们只要专注在分布式技术中最核心的并行处理技术上面,协调我们下面的轮子跑的更快更稳才是我们的最终目标。而数据库底层组件就像车轮一样,经过几十年磨砺,数据库引擎技术已经非常成熟,大可不必去重新设计开发,而且把数据库底层交给其它专业化组织来开发(对应到Postgresql就是社区),还可充分利用到社区的源源不断的创新能力和资源,让产品保持持续旺盛的生命力。
这也是我们在用户选型时,通常建议用户考察一下底层的技术支撑是不是有好的组织和社区支持的原因,如果缺乏这方面的有力支持或独自闭门造轮,那就有理由为那个车的前途感到担忧,一个简单判断的标准就是看看底下那个轮子有多少人使用,有多少人为它贡献力量。
2、为什么是Postgresql而不是其它的?
我想大家可能主要想问为什么是Postgresql而不是Mysql(对不起,还有很多开源关系型数据库,但相比这两个主流开源库,但和这两个大牛比起来,实在不在一个起跑线上)。本文无意去从详细技术点上PK这两个数据库孰优孰劣(网上很多比较),我相信它们的存在都有各自的特点,它们都有成熟的开源社区做支持,有各自的庞大的fans群众基础。个人之见,Greenplum选择Postgressql有以下考虑:
1)Postgresql号称最先进的数据库(官方主页“The world’s most advanced open source database”),且不管这是不是自我标榜,就从OLAP分析型方面来考察,以下几点Postgresql确实胜出一筹:
2)扩展性方面,Postgresql比mysql也要出色许多,Postgres天生就是为扩展而生的,你可以在PG中用Python、C、Perl、TCL、PLSQL等等语言来扩展功能,在后续章节中,我将展现这种扩展是如何的方便,另外,开发新的功能模块、新的数据类型、新的索引类型等等非常方便,只要按照API接口开发,无需对PG重新编译。PG中contrib目录下的各个第三方模块,在GP中的postgis空间数据库、R、Madlib、pgcrypto各类加密算法、gptext全文检索都是通过这种方式实现功能扩展的。
3)在诸如ACID事物处理、数据强一致性保证、数据类型支持、独特的MVCC带来高效数据更新能力等还有很多方面,Postgresql似乎在这些OLAP功能上都比mysql更甚一筹。
4)最后,Postgresql许可是仿照BSD许可模式的,没有被大公司控制,社区比较纯洁,版本和路线控制非常好,基于Postgresql可让用户拥有更多自主性。反观Mysql的社区现状和众多分支(如MariaDB),确实够乱的。
好吧,不再过多列举了,这些特点已经足够了,据说很多互联网公司采用Mysql来做OLTP的同时,却采用Postgresql来做内部的OLAP分析数据库,甚至对新的OLTP系统也直接采用Postgresql。
除此之外,MPP采用两阶段提交和全局事务管理机制来保证集群上分布式事务的一致性,Greenplum像Postgresql一样满足关系型数据库的包括ACID在内的所有特征。
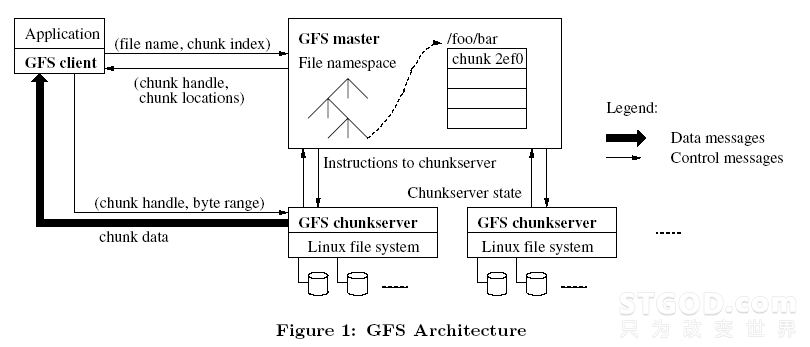
从上图进而可以看到,Greenplum的最小并行单元不是节点层级,而是在实例层级,安装过Greenplum的同学应该都看到每个实例都有自己的postgresql目录结构,都有各自的一套Postgresql数据库守护进程(甚至可以通过UT模式进行单个实例的访问)。正因为如此,甚至一个运行在单节点上的GreenplumDB也是一个小型的并行计算架构,一般一个节点配置6~8个实例,相当于在一个节点上有6~8个Postgresql数据库同时并行工作,优势在于可以充分利用到每个节点的所有CPU和IO 能力。
Greenplum单个节点上运行能力比其它数据库也快很多,如果运行在多节点上,其提供性能几乎是线性的增长,这样一个集群提供的性能能够很轻易的达到传统数据库的数百倍甚至数千倍,所管理数据存储规模达到100TB~数PB,而你在硬件上的投入,仅仅是数台一般的X86服务器和普通的万兆交换机。
Greenplum采用Postgresl作为底层引擎,良好的兼容了Postgresql的功能,Postgresql中的功能模块和接口基本上99%都可以在Greenplum上使用,例如odbc、jdbc、oledb、perldbi、python psycopg2等,所以Greenplum与第三方工具、BI报表集成的时候非常容易;对于postgresql的contrib中的一些常用模块Greenplum提供了编译后的模块开箱即用,如oraface、postgis、pgcrypt等,对于其它模块,用户可以自行将contrib下的代码与Greenplum的include头文件编译后,将动态so库文件部署到所有节点就可进行测试使用了。有些模块还是非常好用的,例如oraface,基本上集成了Oracle常用的函数到Greenplum中,曾经在一次PoC测试中,用户提供的22条Oracle SQL语句,不做任何改动就能运行在Greenplum上。
最后特别提示,Greenplum绝不仅仅只是简单的等同于“Postgresql+interconnect并行调度+分布式事务两阶段提交”,Greenplum还研发了非常多的高级数据分析管理功能和企业级管理模块,这些功能都是Postgresql没有提供的:
- 外部表并行数据加载
- 可更新数据压缩表
- 行、列混合存储
- 数据表多级分区
- Bitmap索引
- Hadoop外部表
- Gptext全文检索
- 并行查询计划优化器和Orca优化器
- Primary/Mirror镜像保护机制
- 资源队列管理
- WEB/Brower监控
前面介绍了Greenplum的分布式并行计算架构,其中每个节点上所有Postgresql实例都是并行工作的,这种并行的Style贯穿了Greenplum功能设计的方方面面:外部表数据加载是并行的、查询计划执行是并行的、索引的建立和使用是并行的,统计信息收集是并行的、表关联(包括其中的重分布或广播及关联计算)是并行的,排序和分组聚合都是并行的,备份恢复也是并行的,甚而数据库启停和元数据检查等维护工具也按照并行方式来设计,得益于这种无所不在的并行,Greenplum在数据加载和数据计算中表现出强悍的性能,某行业客户深有体会:同样2TB左右的数据,在Greenplum中不到一个小时就加载完成了,而在用户传统数据仓库平台上耗时半天以上。
在该用户的生产环境中,1个数百亿表和2个10多亿条记录表的全表关联中(只有on关联条件,不带where过滤条件,其中一个10亿条的表计算中需要重分布),Greenplum仅耗时数分钟就完成了,当其它传统数据平台还在为千万级或亿级规模的表关联性能发愁时,Greenplum已经一骑绝尘,在百亿级规模以上表关联中展示出上佳的表现。
Greenplum建立在Share-nothing无共享架构上,让每一颗CPU和每一块磁盘IO都运转起来,无共享架构将这种并行处理发挥到极致。相比一些其它传统数据仓库的Sharedisk架构,后者最大瓶颈就是在IO吞吐上,在大规模数据处理时,IO无法及时feed数据给到CPU,CPU资源处于wait 空转状态,无法充分利用系统资源,导致SQL效率低下:
一台内置16块SAS盘的X86服务器,每秒的IO数据扫描性能约在2000MB/s左右,可以想象,20台这样的服务器构成的机群IO性能是40GB/s,这样超大的IO吞吐是传统的 Storage难以达到的。
(MPP Share-nothing架构实现超大IO吞吐能力)
另外,Greenplum还是建立在实例级别上的并行计算,可在一次SQL请求中利用到每个节点上的多个CPU CORE的计算能力,对X86的CPU超线程有很好的支持,提供更好的请求响应速度。在PoC中接触到其它一些国内外基于开放平台的MPP软件,大都是建立在节点级的并行,单个或少量的任务时无法充分利用资源,导致系统加载和SQL执行性能不高。
记忆较深的一次PoC公开测试中,有厂商要求在测试中关闭CPU超线程,估计和这个原因有关(因为没有办法利用到多个CPU core的计算能力,还不如关掉超线程以提高单core的能力),但即使是这样,在那个测试中,测试性能也大幅低于Greenplum(那个测试中,各厂商基于客户提供的完全相同的硬件环境,Greenplum是唯一一家完成所有测试的,特别在混合负载测试中,Greenplum的80并发耗时3个多小时就成功完成了,其它厂商大都没有完成此项测试,唯一完成的一家耗时40多小时)
前文提到,得益于Postgresql的良好扩展性(这里是extension,不是scalability),Greenplum 可以采用各种开发语言来扩展用户自定义函数(UDF)(我个人是Python和C的fans,后续章节与大家分享)。这些自定义函数部署到Greenplum后可用充分享受到实例级别的并行性能优势,我们强烈建议用户将库外的处理逻辑,部署到用MPP数据库的UDF这种In-Database的方式来处理,你将获得意想不到的性能和方便性;例如我们在某客户实现的数据转码、数据脱敏等,只需要简单的改写原有代码后部署到GP中,通过并行计算获得数十倍性能提高。
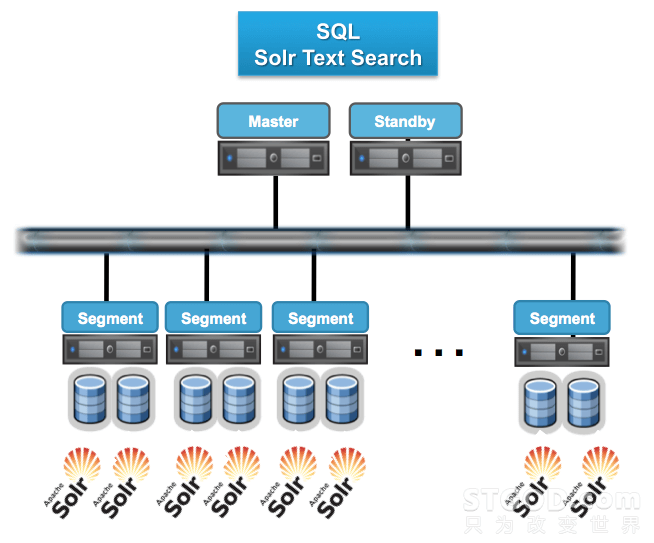
另外,GPTEXT(lucent全文检索)、Apache Madlib(开源挖掘算法)、SAS algorithm、R都是通过UDF方式实现在Greenplum集群中分布式部署,从而获得库内计算的并行能力。这里可以分享的是,SAS曾经做过测试,对1亿条记录做逻辑回归,采用一台小型机耗时约4个多小时,通过部署到Greenplum集群中,耗时不到2分钟就全部完成了。以GPEXT为例,下图展现了Solr全文检索在Greenplum中的并行化风格。
最后,也许有同学会有问题,Greenplum采用Master-slave架构,Master是否会成为瓶颈?完全不用担心,Greenplum所有的并行任务都是在Segment数据节点上完成后,Master只负责生成和优化查询计划、派发任务、协调数据节点进行并行计算。
按照我们在用户现场观察到的,Master上的资源消耗很少有超过20%情况发生,因为Segment才是计算和加载发生的场所(当然,在HA方面,Greenplum提供Standby Master机制进行保证)。
再进一步看,Master-Slave架构在业界的大数据分布式计算和云计算体系中被广泛应用,大家可以看到,现在主流分布式系统都是采用Master-Slave架构,包括:Hadoop FS、Hbase、MapReduce、Storm、Mesos……无一例外都是Master-Slave架构。相反,采用Multiple Active Master 的软件系统,需要消耗更多资源和机制来保证元数据一致性和全局事务一致性,特别是在节点规模较多时,将导致性能下降,严重时可能导致多Master之间的脑裂引发严重系统故障。
Greenplum最大的特点总结就一句话:基于低成本的开放平台基础上提供强大的并行数据计算性能和海量数据管理能力。这个能力主要指的是并行计算能力,是对大任务、复杂任务的快速高效计算,但如果你指望MPP并行数据库能够像OLTP数据库一样,在极短的时间处理大量的并发小任务,这个并非MPP数据库所长。请牢记,并行和并发是两个完全不同的概念,MPP数据库是为了解决大问题而设计的并行计算技术,而不是大量的小问题的高并发请求。
再通俗点说,Greenplum主要定位在OLAP领域,利用Greenplum MPP数据库做大数据计算或分析平台非常适合,例如:数据仓库系统、ODS系统、ACRM系统、历史数据管理系统、电信流量分析系统、移动信令分析系统、SANDBOX自助分析沙箱、数据集市等等。
而MPP数据库都不擅长做OLTP交易系统,所谓交易系统,就是高频的交易型小规模数据插入、修改、删除,每次事务处理的数据量不大,但每秒钟都会发生几十次甚至几百次以上交易型事务 ,这类系统的衡量指标是TPS,适用的系统是OLTP数据库或类似Gemfire的内存数据库。
MPP和Hadoop都是为了解决大规模数据的并行计算而出现的技术,两种技术的相似点在于:
- 分布式存储数据在多个节点服务器上
- 采用分布式并行计算框架
- 支持横向扩展来提高整体的计算能力和存储容量
- 都支持X86开放集群架构
但两种技术在数据存储和计算方法上,也存在很多显而易见的差异:
- MPP按照关系数据库行列表方式存储数据(有模式),Hadoop按照文件切片方式分布式存储(无模式)
- 两者采用的数据分布机制不同,MPP采用Hash分布,计算节点和存储紧密耦合,数据分布粒度在记录级的更小粒度(一般在1k以下);Hadoop FS按照文件切块后随机分配,节点和数据无耦合,数据分布粒度在文件块级(缺省64MB)。
- MPP采用SQL并行查询计划,Hadoop采用Mapreduce框架
基于以上不同,体现在效率、功能等特性方面也大不相同:
1.计算效率比较:
先说说Mapreduce技术,Mapreduce相比而言是一种较为蛮力计算方式(业内曾经甚至有声音质疑MapReduce是反潮流的),数据处理过程分成Map-〉Shuffle-〉Reduce的过程,相比MPP 数据库并行计算而言,Mapreduce的数据在计算前未经整理和组织(只是做了简单数据分块,数据无模式),而MPP预先会把数据有效的组织(有模式),例如:行列表关系、Hash分布、索引、分区、列存储等、统计信息收集等,这就决定了在计算过程中效率大为不同:
- Hadoop的MAP阶段需要对数据的再解析,而MPP数据库直接取行列表,效率高
- Hadoop按照64MB分拆文件,而且数据不能保证在所有节点均匀分布,因此MAP过程的并行化程度低;MPP数据库按照数据记录拆分和Hash分布,粒度更细,数据分布在所有节点中非常均匀,并行化程度很高
- Hadoop HDFS没有灵活的索引、分区、列存储等技术支持,而MPP通常利用这些技术大幅提高数据的检索效率;
- 由于Hadoop数据与节点的无关性,因此Shuffle是基本避免不了的;而MPP数据库对于相同Hash分布数据不需要重分布,节省大量网络和CPU消耗;
- Mapreduce没有统计信息,不能做基于cost-base的优化;MPP数据库利用统计信息可以很好的进行并行计算优化,例如,对于不同分布的数据,可以在计算中基于Cost动态的决定最优执行路径,如采用重分布还是小表广播
- Mapreduce缺乏灵活的Join技术支持,MPP数据库可以基于COST来自动选择Hash join、Merger join和Nestloop join,甚至可以在Hash join通过COST选择小表做Hash,在Nestloop Join中选择index提高join性能等等;
- MPP数据库对于Aggregation(聚合)提供Multiple-agg、Group-agg、sort-agg等多种技术来提供计算性能,Mapreuce需要开发人员自己实现;
总结以上几点,MPP数据库在计算并行度、计算算法上比Hadoop更加SMART,效率更高;在客户现场的测试对比中,Mapreduce对于单表的计算尚可,但对于复杂查询,如多表关联等,性能很差,性能甚至只有MPP数据库的几十分之一甚至几百分之一,下图是基于MapReduce的Hive和Greenplum MPP在TPCH 22个SQL测试性能比较:(相同硬件环境下)
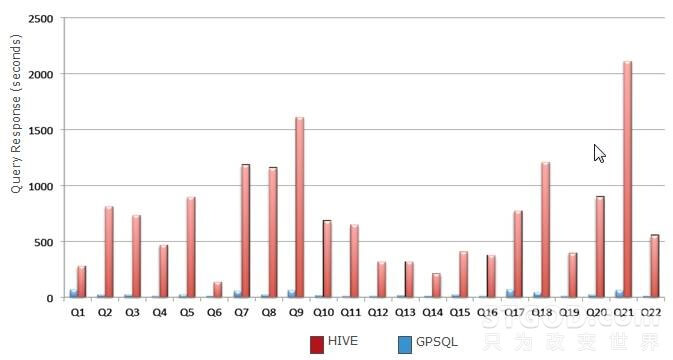
还有,某国内知名电商在其数据分析平台做过验证,同样硬件条件下,MPP数据库比Hadoop性能快12倍以上。
2.功能上的对比
MPP数据库采用SQL作为主要交互式语言,SQL语言简单易学,具有很强数据操纵能力和过程语言的流程控制能力,SQL语言是专门为统计和数据分析开发的语言,各种功能和函数琳琅满目,SQL语言不仅适合开发人员,也适用于分析业务人员,大幅简化了数据的操作和交互过程。
而对MapReduce编程明显是困难的,在原生的Mapreduce开发框架基础上的开发,需要技术人员谙熟于JAVA开发和并行原理,不仅业务分析人员无法使用,甚至技术人员也难以学习和操控。为了解决易用性的问题,近年来SQL-0N-HADOOP技术大量涌现出来,几乎成为当前Hadoop开发使用的一个技术热点趋势。
这些技术包括:Hive、Pivotal HAWQ、SPARK SQL、Impala、Prest、Drill、Tajo等等很多,这些技术有些是在Mapreduce上做了优化,例如Spark采用内存中的Mapreduce技术,号称性能比基于文件的的Mapreduce提高10倍;有的则采用C/C++语言替代Java语言重构Hadoop和Mapreuce(如MapR公司及国内某知名电商的大数据平台);而有些则直接绕开了Mapreduce另起炉灶,如Impala、hawq采用借鉴MPP计算思想来做查询优化和内存数据Pipeline计算,以此来提高性能。
虽然SQL-On-Hadoop比原始的Mapreduce虽然在易用上有所提高,但在SQL成熟度和关系分析上目前还与MPP数据库有较大差距:
- 上述系统,除了HAWQ外,对SQL的支持都非常有限,特别是分析型复杂SQL,如SQL 2003 OLAP WINDOW函数,几乎都不支持,以TPC-DS测试(用于评测决策支持系统(大数据或数据仓库)的标准SQL测试集,99个SQL)为例,包括SPARK、Impala、Hive只支持其中1/3左右;
- 由于HADOOP 本身Append-only特性,SQL-On-Hadoop大多不支持数据局部更新和删除功能(update/delete);而有些,例如Spark计算时,需要预先将数据装载到DataFrames模型中;
- 基本上都缺少索引和存储过程等等特征
- 除HAWQ外,大多对于ODBC/JDBC/DBI/OLEDB/.NET接口的支持有限,与主流第三方BI报表工具兼容性不如MPP数据库
- SQL-ON-HADOOP不擅长于交互式(interactive)的Ad-hoc查询,多通过预关联的方式来规避这个问题;另外,在并发处理方面能力较弱,高并发场景下,需要控制计算请求的并发度,避免资源过载导致的稳定性问题和性能下降问题;
3.架构灵活性对比:
前文提到,为保证数据的高性能计算,MPP数据库节点和数据之间是紧耦合的,相反,Hadoop的节点和数据是没有耦合关系的。这就决定了Hadoop的架构更加灵活-存储节点和计算节点的无关性,这体现在以下2个方面:
- Hadoop架构支持单独增加数据节点或计算节点,依托于Hadoop的SQL-ON-HADOOP系统,例如HAWQ、SPARK均可单独增加计算层的节点或数据层的HDFS存储节点,HDFS数据存储对计算层来说是透明的;
- MPP数据库扩展时,一般情况下是计算节点和数据节点一起增加的,在增加节点后,需要对数据做重分布才能保证数据与节点的紧耦合(重新hash数据),进而保证系统的性能;Hadoop在增加存储层节点后,虽然也需要Rebalance数据,但相较MPP而言,不是那么紧迫。
- Hadoop节点宕机退服,对系统的影响较小,并且系统会自动将数据在其它节点扩充到3份;MPP数据库节点宕机时,系统的性能损耗大于Hadoop节点。
Pivotal将GPDB 的MPP技术与Hadoop分布式存储技术结合,推出了HAWQ高级数据分析软件系统,实现了Hadoop上的SQL-on-HADOOP,与其它的SQL-on-HADOOP系统不同,HAWQ支持完全的SQL语法 和SQL 2003 OLAP 语法及Cost-Base的算法优化,让用户就像使用关系型数据库一样使用Hadoop。底层存储采用HDFS,HAWQ实现了计算节点和HDFS数据节点的解耦,采用MR2.0的YARN来进行资源调度,同时具有Hadoop的灵活伸缩的架构特性和MPP的高效能计算能力.
当然,有得也有所失,HAWQ的架构比Greenplum MPP数据库灵活,在获得架构优越性的同时,其性能比Greenplum MPP数据库要低一倍左右,但得益于MPP算法的红利,HAWQ性能仍大幅高于其它的基于MapReduce的SQL-on-HADOOP系统。
4.选择MPP还是Hadoop
总结一下,Hadoop MapReduce和SQL-on-HADOOP技术目前都还不够成熟,性能和功能上都有很多待提升的空间,相比之下,MPP数据在数据处理上更加SMART,要填平或缩小与MPP数据库之间的性能和功能上的GAP,Hadoop还有很长的一段路要走。
就目前来看,个人认为这两个系统都有其适用的场景,简单来说,如果你的数据需要频繁的被计算和统计、并且你希望具有更好的SQL交互式支持和更快计算性能及复杂SQL语法的支持,那么你应该选择MPP数据库,SQL-on-Hadoop技术还没有Ready。特别如数据仓库、集市、ODS、交互式分析数据平台等系统,MPP数据库有明显的优势。
而如果你的数据加载后只会被用于读取少数次的任务和用于少数次的访问,而且主要用于Batch(不需要交互式),对计算性能不是很敏感,那Hadoop也是不错的选择,因为Hadoop不需要你花费较多的精力来模式化你的数据,节省数据模型设计和数据加载设计方面的投入。这些系统包括:历史数据系统、ETL临时数据区、数据交换平台等等。
总之,Bear in mind,千万不要为了大数据而大数据(就好像不要为了创新而创新一个道理),否则,你项目最后的产出与你的最初设想可能将差之千里,行业内不乏失败案例。
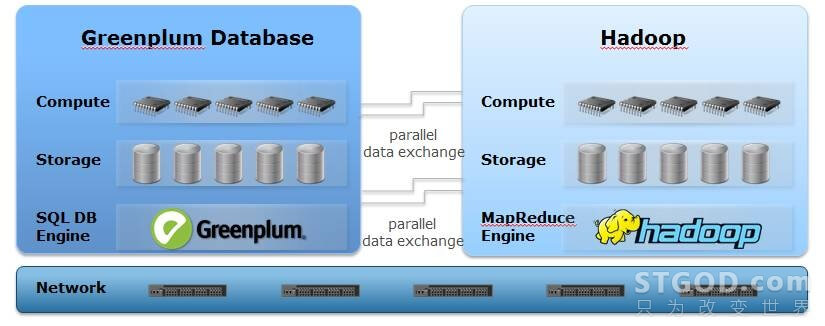
最后,提一下,Greenplum MPP数据库支持用“Hadoop外部表”方式来访问、加载Hadoop FS的数据,虽然Greenplum的Hadoop外部表性能大幅低于MPP内部表,但比Hadoop 自身的HIVE要高很多(在某金融客户的测试结果,比HIVE高8倍左右),因此可以考虑在项目中同时部署MPP数据库和Hadoop,MPP用于交互式高性能分析,Hadoop用于数据Staging、MPP的数据备份或一些ETL batch的数据清洗任务,两者相辅相成,在各自最擅长的场景中发挥其特性和优势。
5.未来GP发展之路
过去十年,IT技术潮起潮落发生着时刻不停的变化,而在这变化中的不变就是走向开放和开源的道路,即将到来的伟大变革是云计算时代的到来,任何IT技术,从硬件到软件到服务,都逃不过要接受云计算的洗礼,不能赶上时代潮流的技术和公司都将被无情的淘汰。大数据也要拥抱云计算,大数据将作为一种数据服务来提供(DaaS-Data as A Service),依靠云提供共享的、弹性、按需分配的大数据计算和存储的服务。
Greenplum MPP数据库从已一开始就是开放的技术,并且在2015年年底已经开源和成立社区(在开源第一天就有上千个Download),可以说,Greenplum已经不仅仅只是Pivotal公司一家的产品,我们相信越来越多组织和个人会成为Greenplum的Contributor贡献者,随着社区的发展将推动Greenplum MPP数据库走向新的高速发展旅程。(分享一下开源的直接好处,最近我们某用户的一个特殊需求,加载数据中有回车等特殊字符,我们下载了GP外部表gpfdist源代码,不到一天就轻松搞定问题)
Greenplum也正在积极的拥抱云计算,Cloud Foundry的PaaS云平台正在技术考虑把Greenplum MPP做为DaaS服务来提供,对于Mesos或其它云计算技术的爱好者,也可以考虑采用容器镜像技术+集群资源框架管理技术来部署Greenplum,从而可以实现在公共计算资源集群上的MPP敏捷部署和资源共享与分配。
总之,相信沿着开放、开源、云计算的路线继续前行,Greenplum MPP数据库在新的时代将保持旺盛的生命力,继续高速发展。
作者:STGOD
转载请标明出处:https://stgod.com/2450/